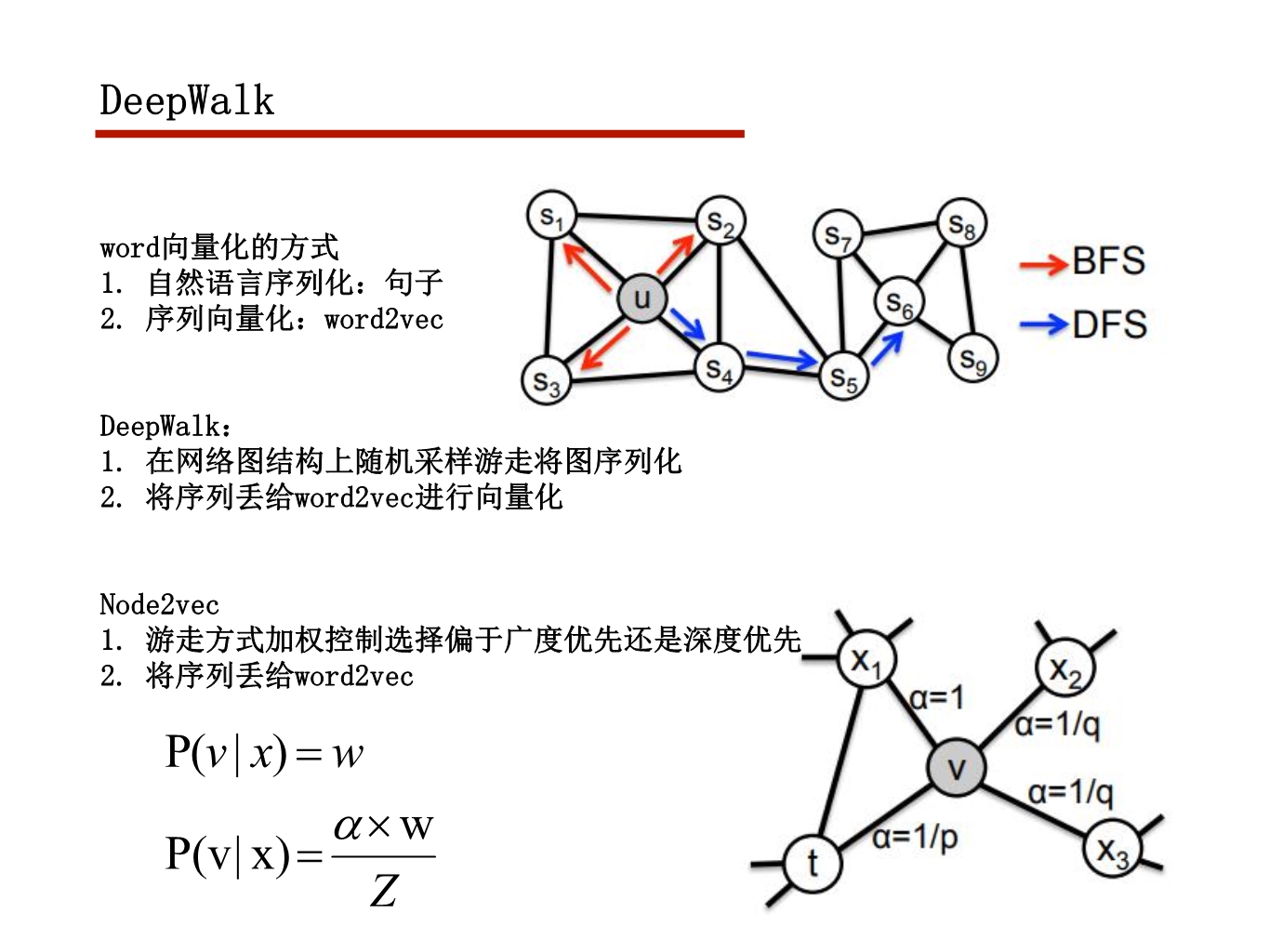
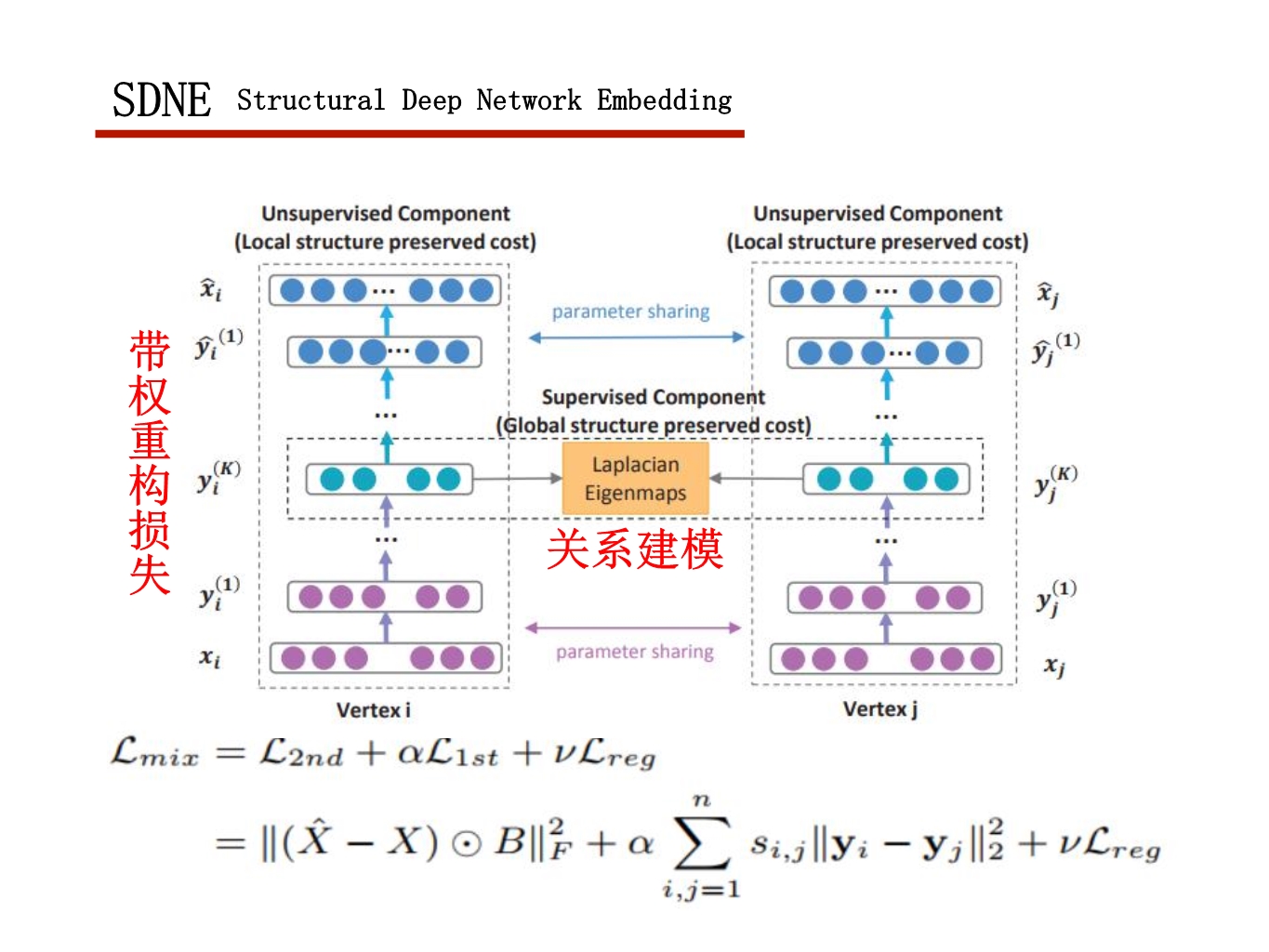
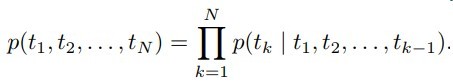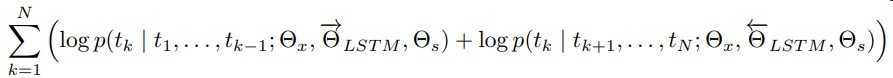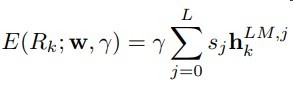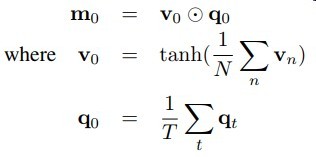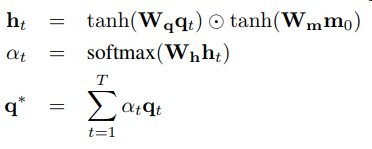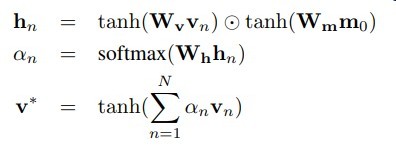这几天被BERT刷屏了
结果是真的好看,刷新了十一项记录,每项都有巨大改进…
下面分析一下这篇文章的工作
Input
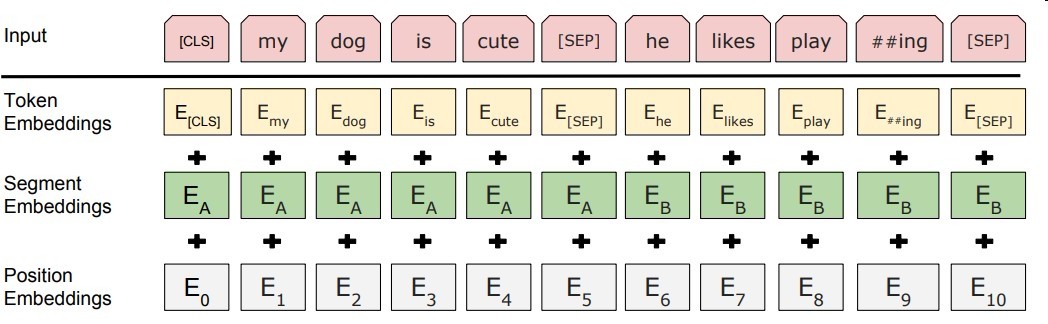
一个句子对,即两个句子
- WordPiece Embedding
这个东西是用来解决oov的word的,将部分单词拆成两个字词,如fued拆成fu,ed .
具体怎么拆,拆哪些,用贪心算法搜索尽可能少的token去覆盖所有单词 - Segment Embedding
区分是句子一还是句子二 - Position Embedding
融入位置信息,学习得到 - cls是句子的类别信息,用于task2和其他任务(非分类任务可无视)
- [SEP]是句子的分隔符
下面是该论文的自监督任务的两个创新点
TASK1 #: MLM(masked language model)
随机屏蔽batchsize samples中一定量的单词,并去预测他 (完形填空)
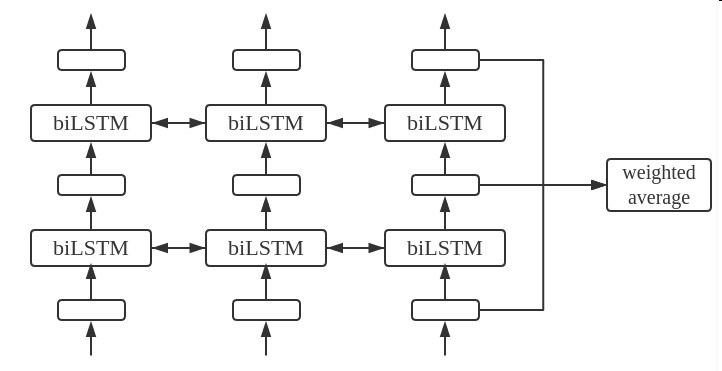
- 使用bidirectional self-attention
不使用rnn可能是因为网络很深不好训练.
作者认为用单项模型然后两向使用再拼接不如直接双向来的自然,能更好的捕捉上下文信息 - 每次屏蔽每个句子中15%的单词
(1)80%的概率将单词换为[mask]标记 , my dog is hairy → my dog is [MASK]
(2)10%的概率将单词换为字表中其他单词 , my dog is hairy → my dog is apple
(3)10%的概率不替换 , my dog is hairy → my dog is hairy
具体为什么不是很清楚.. (2)可能是加噪缓解过拟合,(3)不知道了…
TASK2 #: NSP(Next Sentence Prediction)
由于输入的是一个句子对,所以这个任务是去判断句子二是否可作为句子一的下一句
这个任务的目的应该是学习句子之间的逻辑关系
summary
下图是在其他任务的微调方式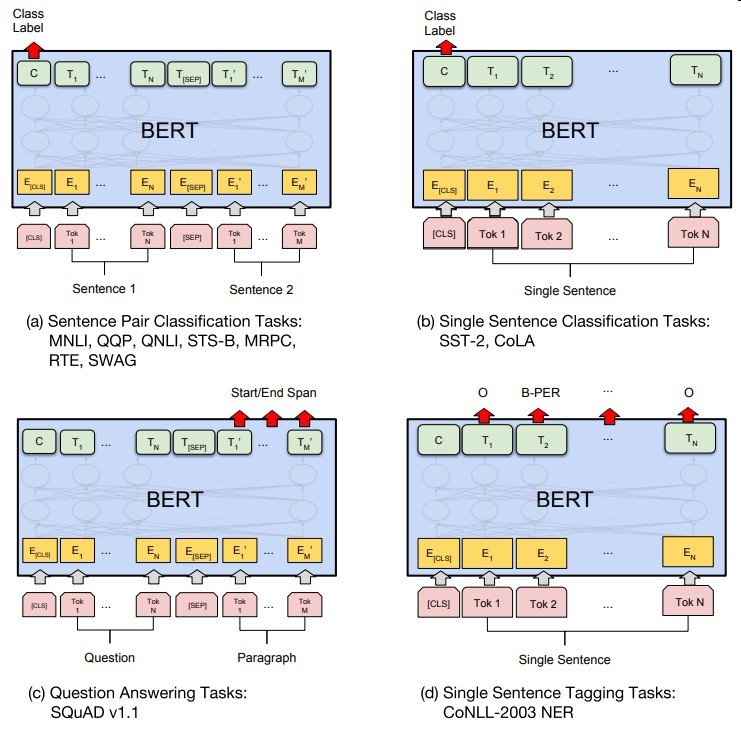
由于每次只屏蔽一部分
这比left2right收敛慢很多
一般来讲自监督的模型一般有比较好的泛化效果
然后结果也很惊人…
最后就是模型好大…用不起用不起…