这是一篇应用了attention在图像分割的文章
文章本身很简单,感觉工作不多
最近在vqa工作中对attention体会很深,也创新了不少东西
在结束后再写篇博文吧
回到正文
整体架构
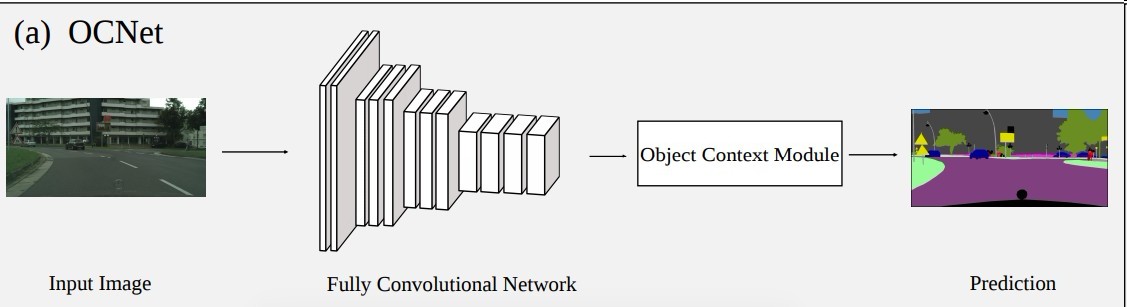
恩 … 整体框架还是无特别大的创新
Object Context
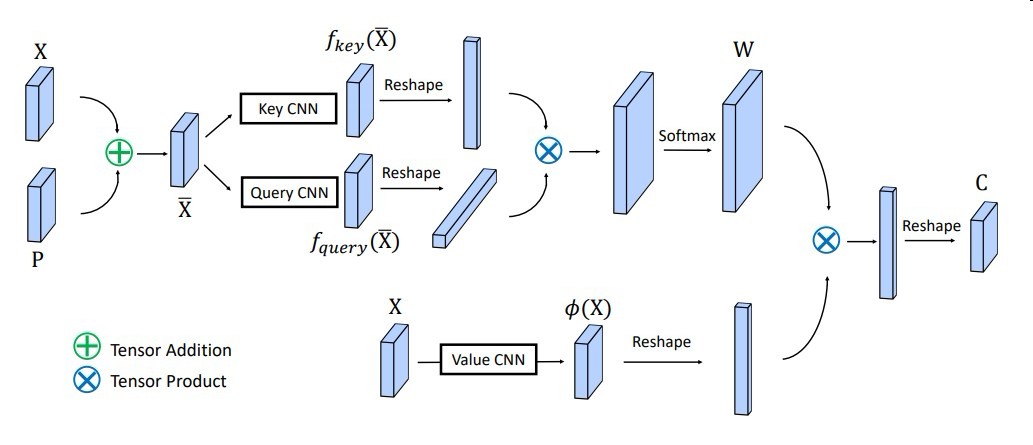
输出的C指context
P指Position embedding
X+P将位置信息融入feature map
再做个很普通的attention
就是以像素为单位,以余弦相关性作为相似度度量.
获得了context他的使用方式如下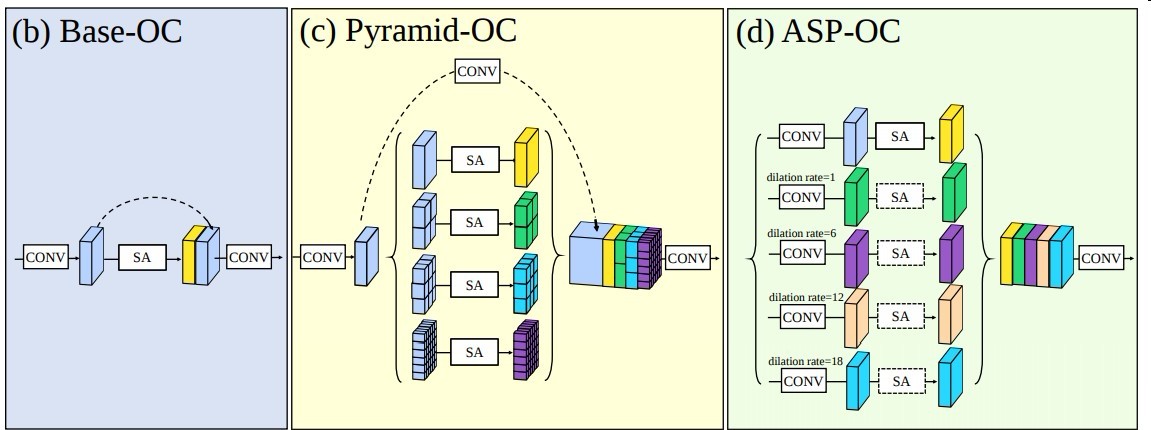
配合hypercolumn或ASP
最后
其实感觉Context插入的很强行
self-attention其实有跨大距离依赖效果才比conv强的
相比于self-attention
分割这种感受野任务,给channel加attention(不同感受野feature map拼接后权重不同)效果更佳
效果也只有几个千分点的提升,表示质疑
朋友测试下效果也不是很好…
而且他的注意力是直接用softmax的
对于这么多像素做softmax 有效信息被无效信息覆盖的情况一般都很严重…
我严重怀疑这个和average效果差不多
他可以试试半hard半soft的attention