需求所致简单入门一下vqa
Sequential Co-Attention
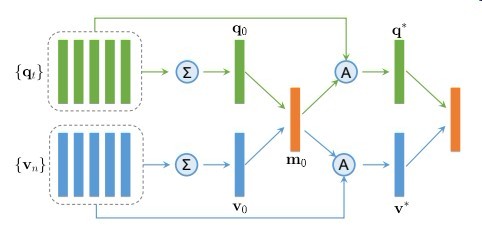
如图所示
这是16年11月份一个序列协同注意力结构
直接放公式吧
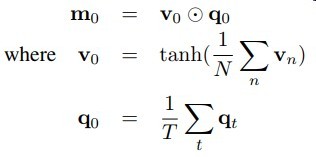
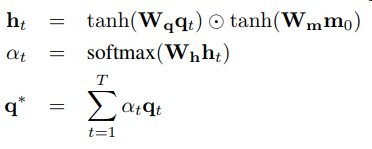
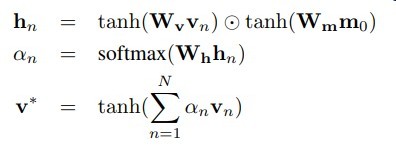
思路比较简单
{qt} question(word sequence)
{vn} 是通过一个backbone后再reshape的”区域”序列
如vgg16 -> 1616512 -> 256*512 每个像素代表一个区域
然后对图片的每个区域以及question的每个时间步做相关性计算
获得注意力权重加权….
Memory Augmented Network
这里使用了Memory Network
是本文的创新点貌似
用(xt,yt)代表一个样本
t表示样本喂给模型的顺序
以LSTM 作为Memory Net的controller
ht = LSTM(xt , ht-1)
每次基于内容寻址
将ht与所有记忆单元计算相似度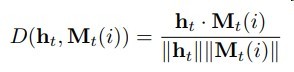
然后用softmax规范化相似度作为权重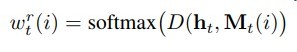
加权获得历史信息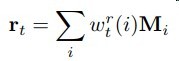
与ht拼接放入分类网络
更新历史信息单元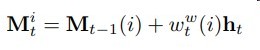
结束
结语
作为一个放入VQA的小萌新
刷了几篇感觉好像比我想象中的要easy很多