ELMo 是NAACL2018的best paper
早就想读了了,攒着一直没读…
其实nn的文章看图能识个大概了,接着再细读其中细节
但这篇文章没图…
下面上一张自制的
ELMo结构与使用方式
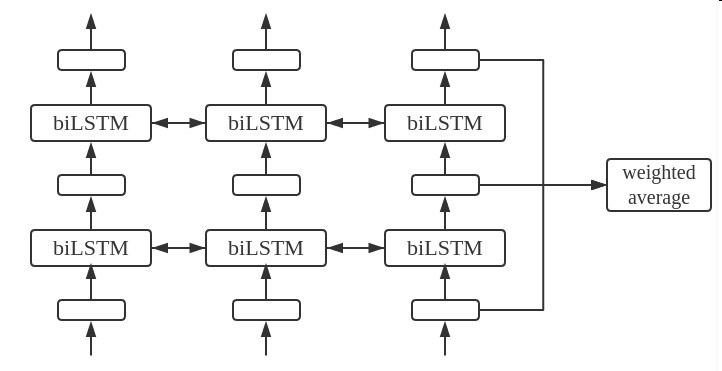
如图,上面是ELMo的使用方式
将模型中word在LSTM中输出的中间态作为他的embedding
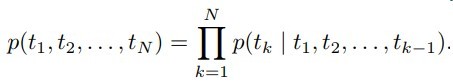
他自己则是一个多层双向语言自监督模型
正向预测和逆向预测word作为task,进行训练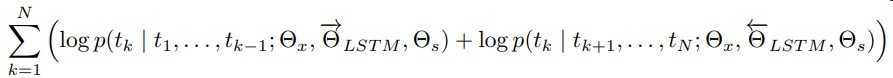
这种设计个人认为有如下几点好处
- word在不同语境有不同意思,使用LSTM中间状态带入了上下文信息解决了语义歧义的问题
- biLSTM相比Glove,word2vec带入了语序信息
- biLSTM能捕捉一定的语法结构信息
使用方式
冷冻biLM模型
将他各个中间层的信息加权平均,再和普通的词向量concat
公式如下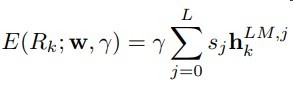
stask是可训练且经过softmax归一化的权重
stask用于在不同任务下自适应调整高维还是低维的抽象信息
γ是缩放因子,对模型影响较大,可训练