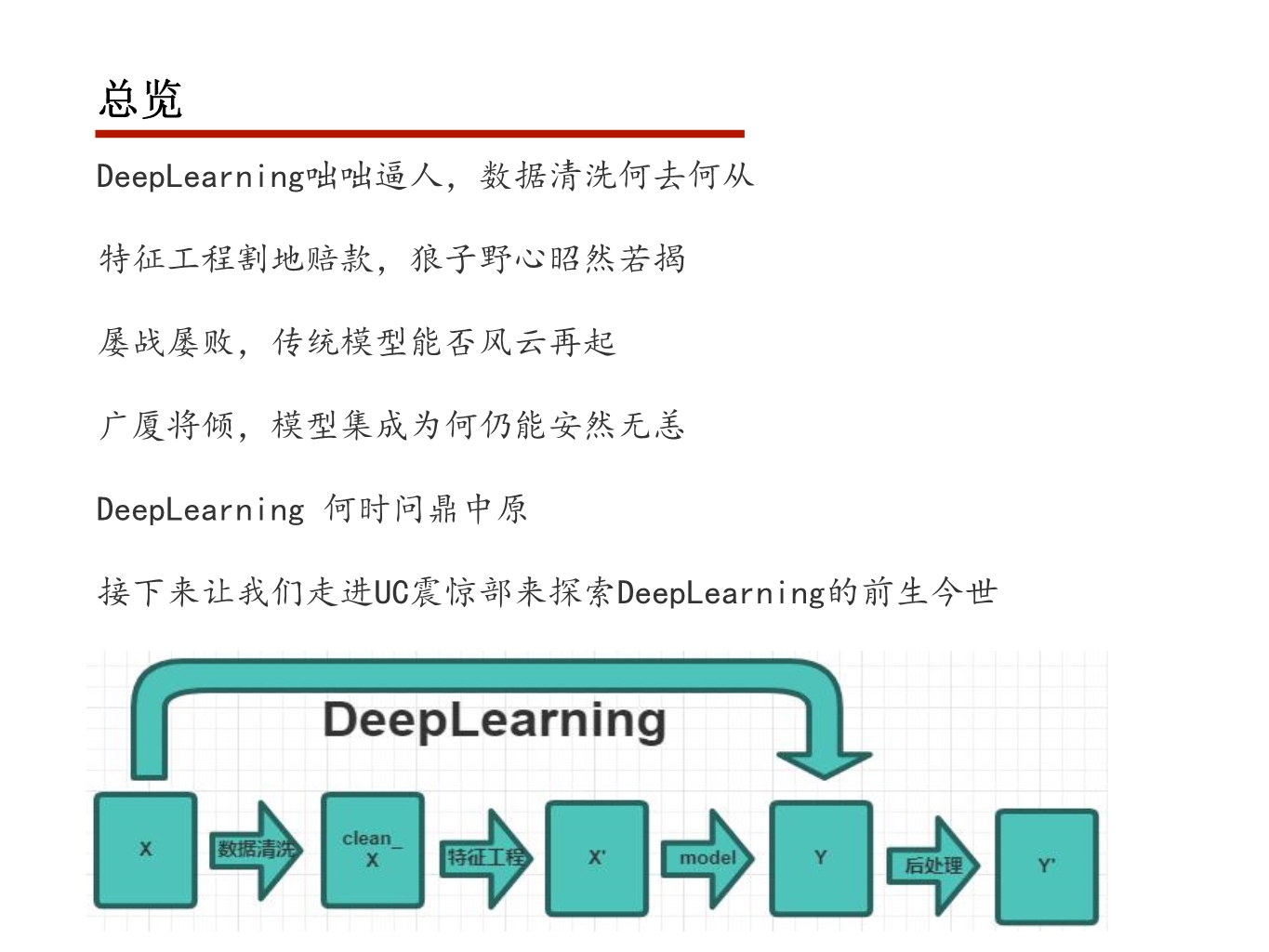
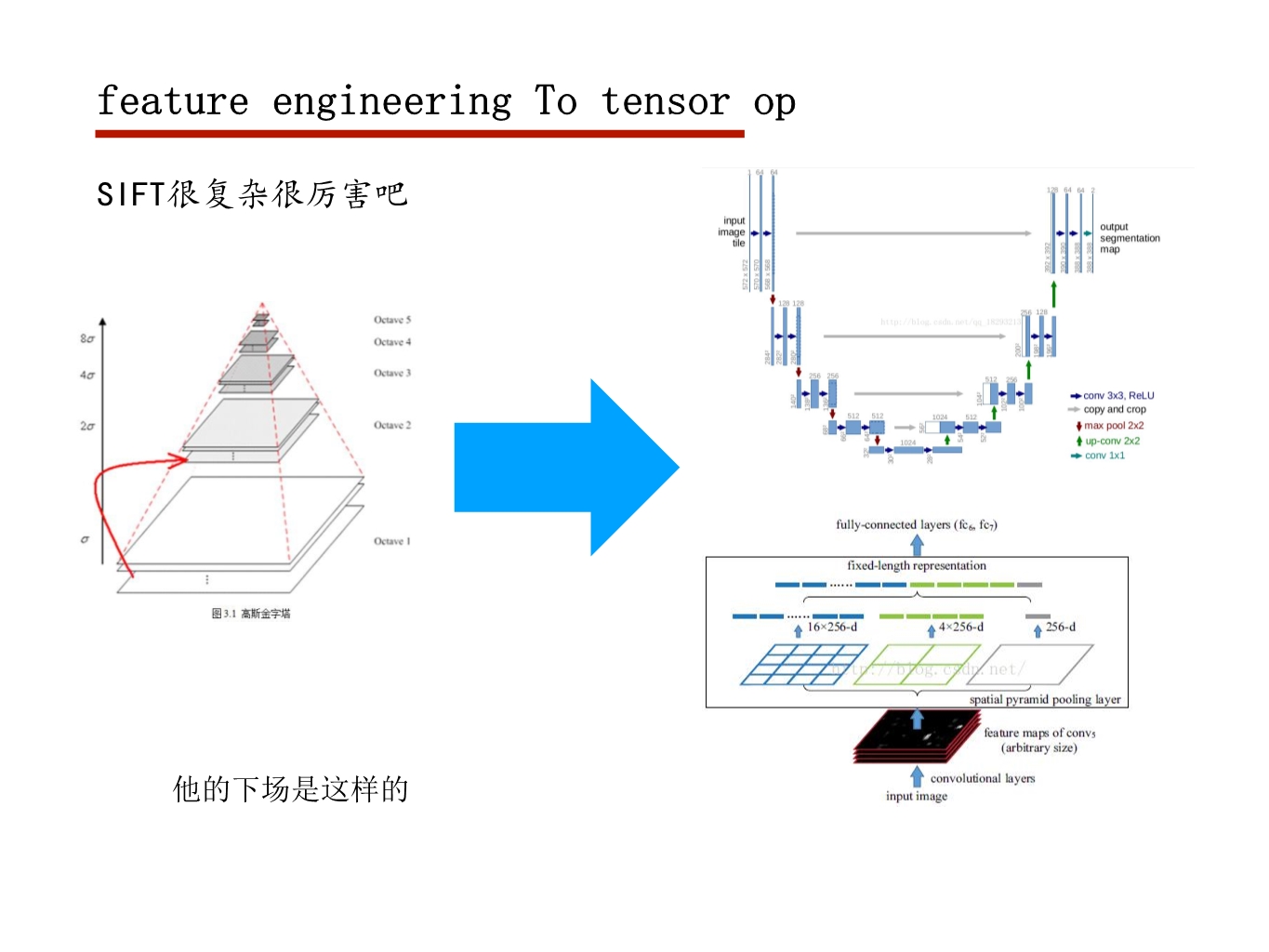
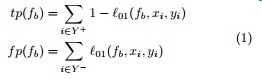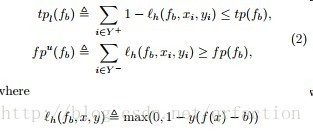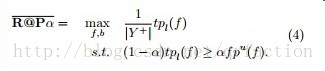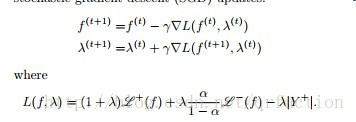OpenMP基于共享内存的线程级并行计算
支持的编程语言包括C、C++和Fortran
只需要在适当的位置添加pragma就可以将程序自动并行处理
当编译器不支持OpenMP时,程序会退化成普通(串行)程序
并行指令
parallel指令
#include "omp.h"
#include "iostream"
#include "stdlib.h"
using namespace std;
int main(){
#pragma omp parallel num_threads(6)
{
cout<<"hello world"<<endl;
}
}
编译运行 g++ test.cpp -fopenmp -lpthread
代码输出如下
hello world
hello worldhello world
hello world
hello worldhello world
使用OpenMP必加 #pragma omp 前缀
parallel可以使得后续代码块并行执行,默认是机器核心数,若加了num_threads(6)语句则开启6个线程
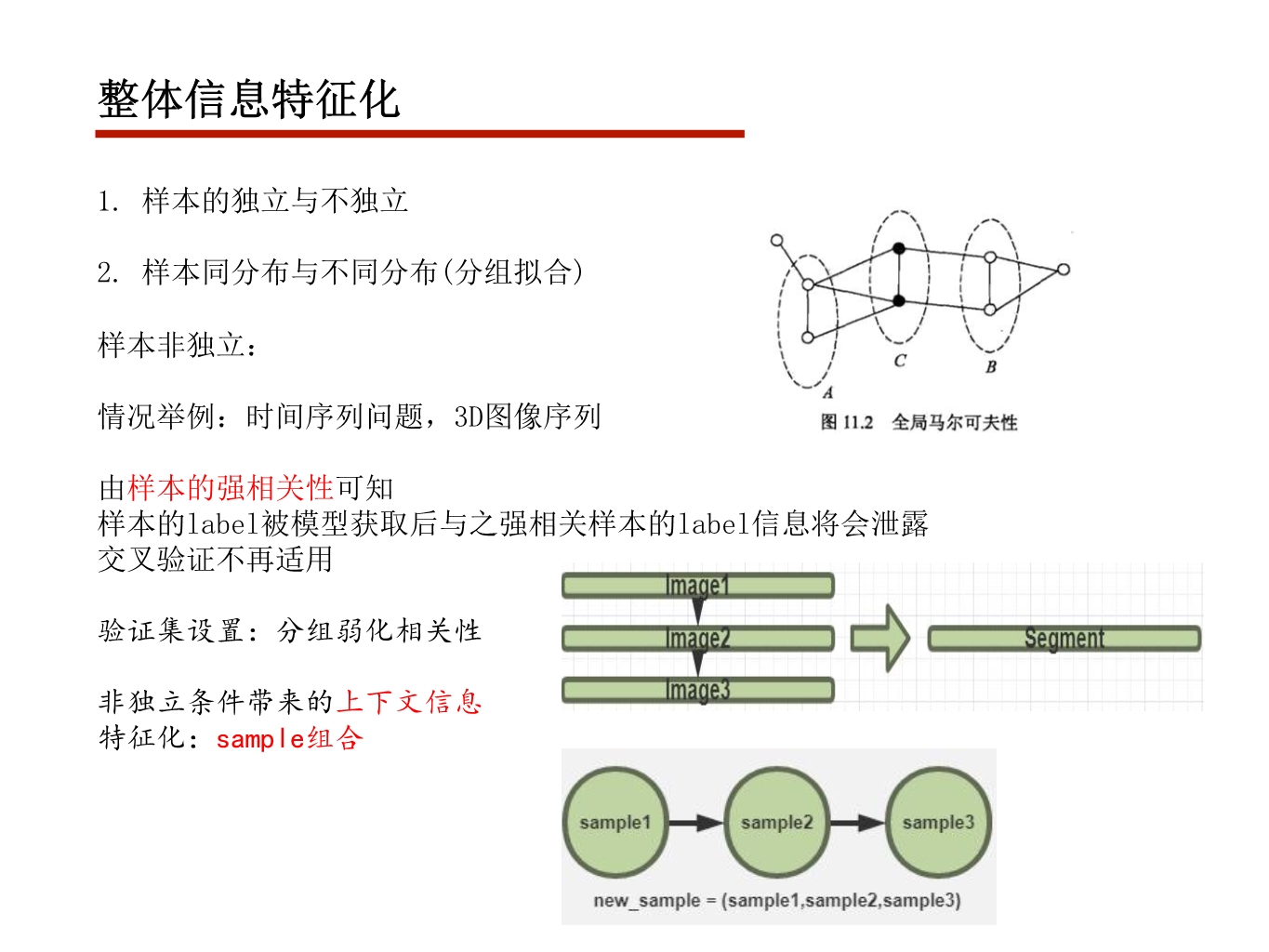
OpenMP采用fork-join执行模型
在进入代码块前开启多个线程,最后再阻塞等待所有线程执行结束退出代码块
prallel for指令
#include "omp.h"
#include "iostream"
#include <stdlib.h>
using namespace std;
int main(){
#pragma omp parallel for
for(int i=0;i<omp_get_num_procs();++i)
cout<<"thread id : "
<<omp_get_thread_num()<<endl;
}
代码输出如下
thread id : thread id : thread id : thread id : 21
0
3
int omp_get_num_procs() 返回机器核心数
int omp_get_thread_num() 返回当前线程id(话说这名字起的…)
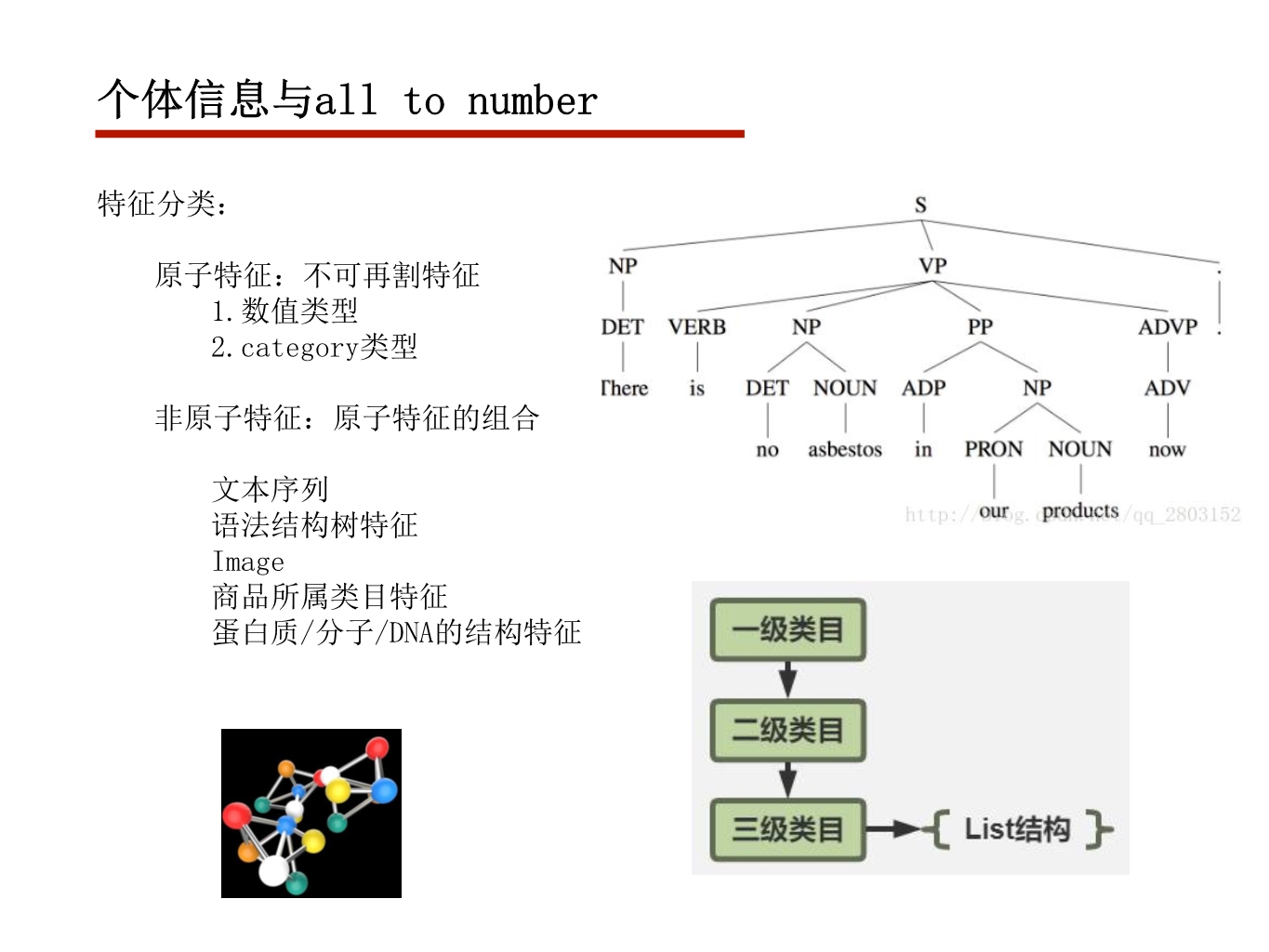
其中parallel for 指令并非能并行所有for循环,要满足如下条件
1. for循环中的循环变量必须是有int 即int i
2. for循环中比较操作符必须是<, <=, >, >= ,如!=等会编译不通过
3. 第三个表达式必须是循环变量的加减,且似乎只能++i, i++, -–i, 或i-–
4. 循环体内部不许出现到达循环体外的跳转语句如break,goto,但exit除外
sections指令
int main(){
#pragma omp parallel sections
{
#pragma omp section
{
for(int i=0;i<4;++i)
printf("i:%i \t id:%d\n",i,omp_get_thread_num());
}
#pragma omp section
{
for(int i=0;i<4;++i)
printf("i:%i \t id:%d\n",i,omp_get_thread_num());
}
}
}
程序执行结果如下
i:0 id:1
i:1 id:1
i:2 id:1
i:3 id:1
i:0 id:3
i:1 id:3
i:2 id:3
i:3 id:3
sections指令中的section指定的代码块将会并行执行
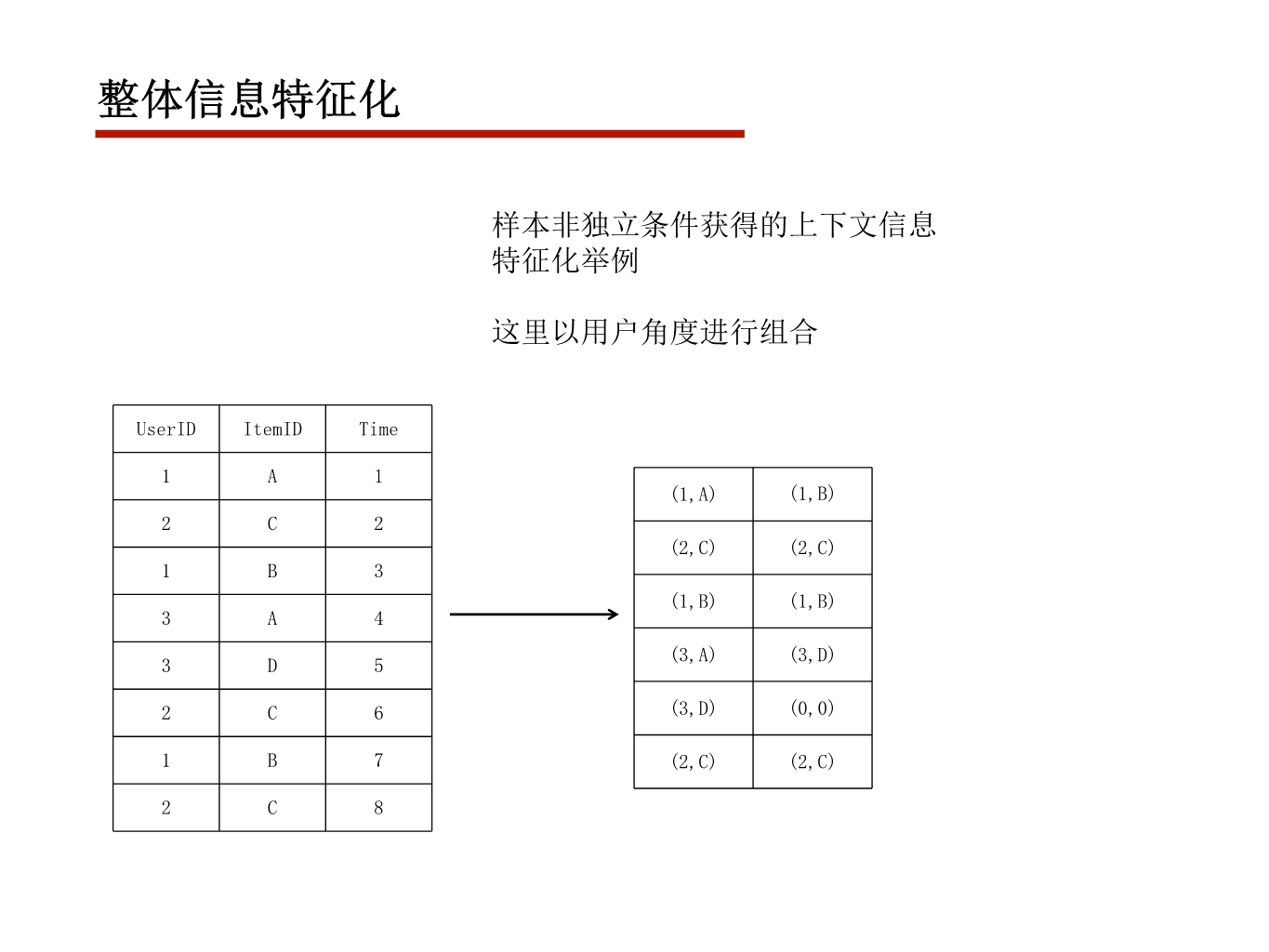
数据共享
#include "omp.h"
#include "iostream"
#include <stdlib.h>
using namespace std;
int main(){
int a=10;
#pragma omp parallel for firstprivate(a)
for(int i=0;i<10;++i)
cout << a*i << endl;
}
firstprivate子句在每个线程中声明了a变量,并以外部的a变量的值进行初始化
代码运行结果如下
30
40
50
80
90
0
10
20
60
70
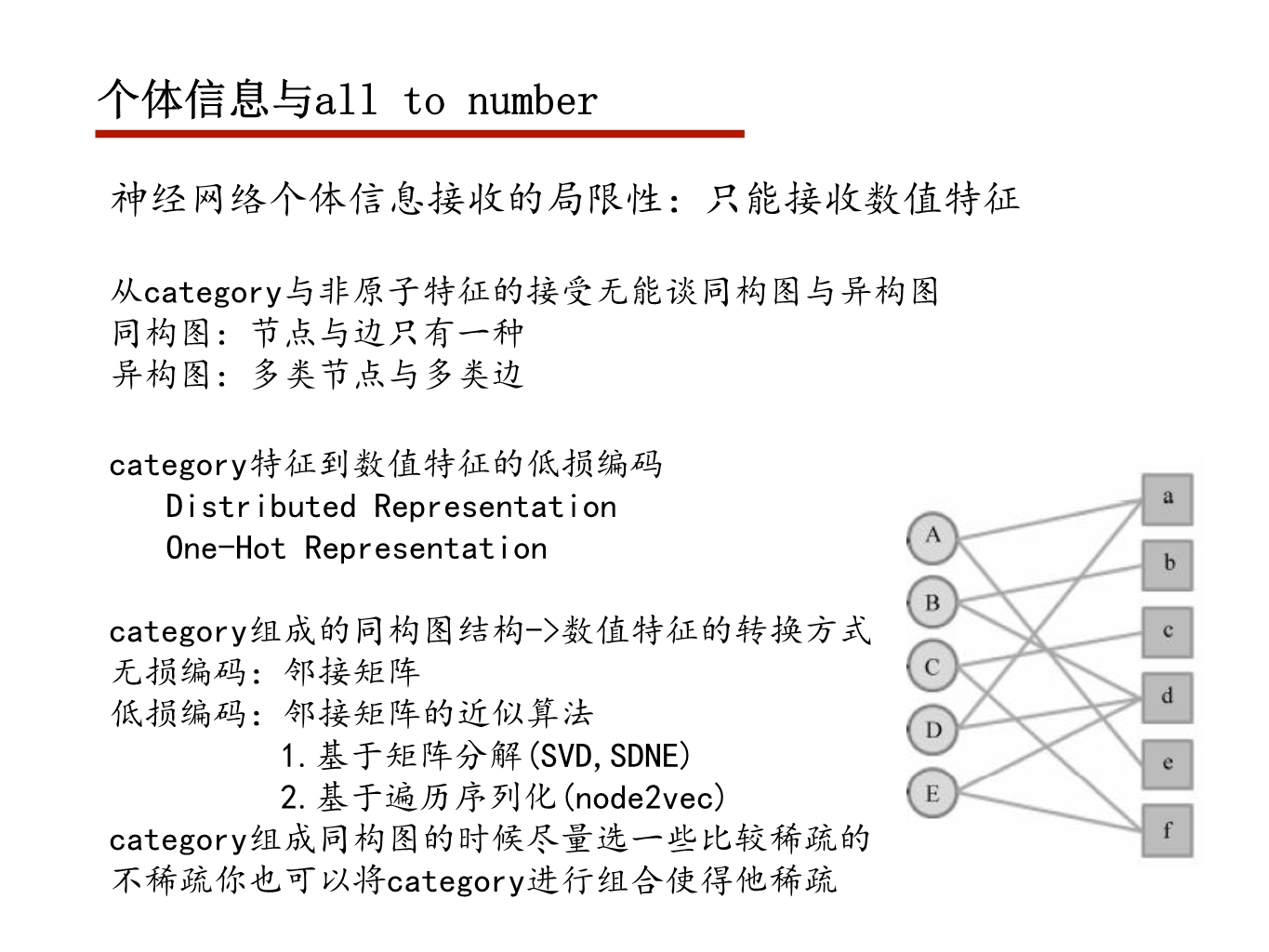
子句 private(val1, val2, …)
声明私有变量,但值与外部变量不同,全部初始化为0
子句 last_private(val1, val2, …)
将会把并行区域中最后一次执行对val1的操作后的值将会拷贝到相应外部变量中
shared(val1, val2, …)
声明这些变量共享(其实并行区域外的变量默认是共享的)
reduction子句
#include "omp.h"
#include "iostream"
#include <stdlib.h>
using namespace std;
int main(){
int sum=10;
#pragma omp parallel for reduction(+:sum)
for(int i=0;i<10;++i){
sum +=i;
cout << sum << endl;
}
cout<<"sum "<<sum<<endl;
}
在这里每个线程首先拷贝了一份外部的sum并各自计算
最后以指定的运算”+”进行归约(reduction),将各线程的结果求和
最后退出代码块将值拷贝到外部的sum