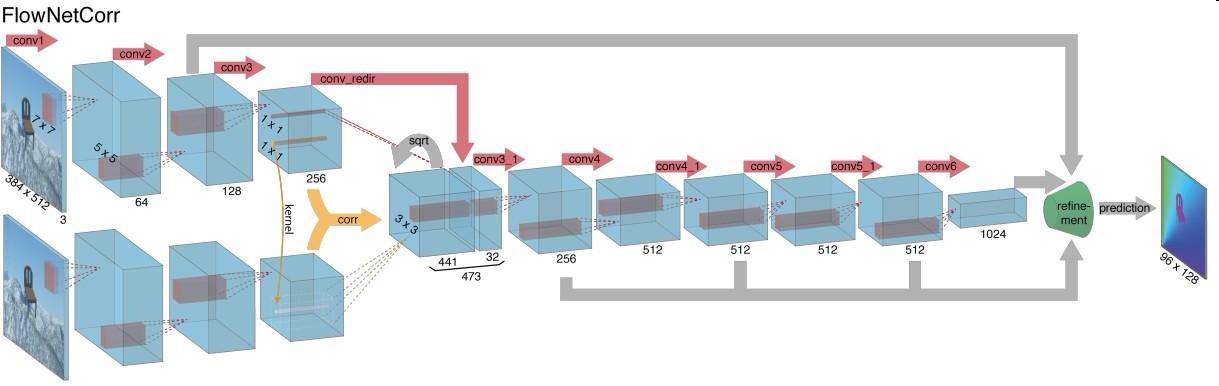
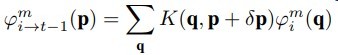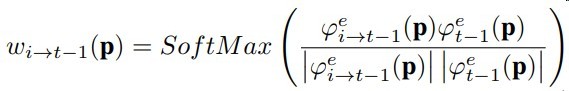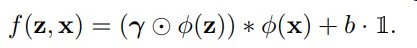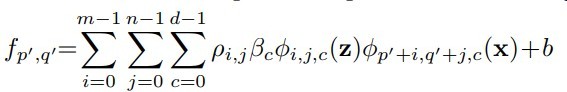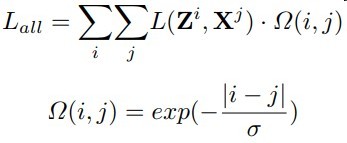这些天的work和循环单元很相关
于是看了这篇很早就想看的IndRNN
不得不说work很好看
简单but略完美
传统循环单元一般只能坚持到几百步长
而他能坚持到5000!!!!!!
emmm
还有前天和鹏哥在微博上吹逼,吹错了
今天细看文章的时候发现的,真是尴尬hh
IndRNN介绍
IndRNN和传统RNN的定义式区别见下图
RNN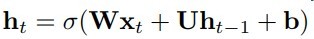
IndRNN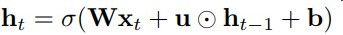
整个区别真的只有矩阵乘法转为hadamard积(对应元素相乘)
其中每个ht使用的是不同的u向量权重
然后IndRNN一般采用relu激活
改动虽小,作用却大
梯度分析传统RNN和IndRNN
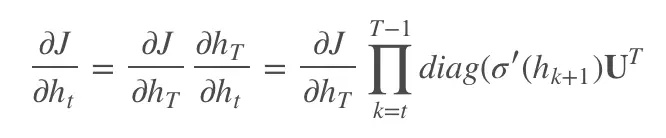
由梯度计算式可知传统RNN的连乘,由于这个原因导致了梯度爆炸和消失…
而再来观察IndRNN梯度的表达式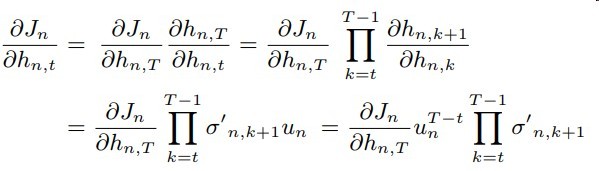
如果采用relu激活,后面部分的梯度连乘不会造成梯度爆炸
而un的大小不会影响到h其他时间步的梯度
即由矩阵乘法转为hadamard积将梯度计算在一定程度上隔离开来了
un是hn,t-1的权重而不会影响到其他时间步
而u只需约束到一个范围即可完美解决梯度消失与爆炸
见下图(其实我觉得没屁用,RNN不也可以这样吗)