cv讨论班自己做的简短汇报
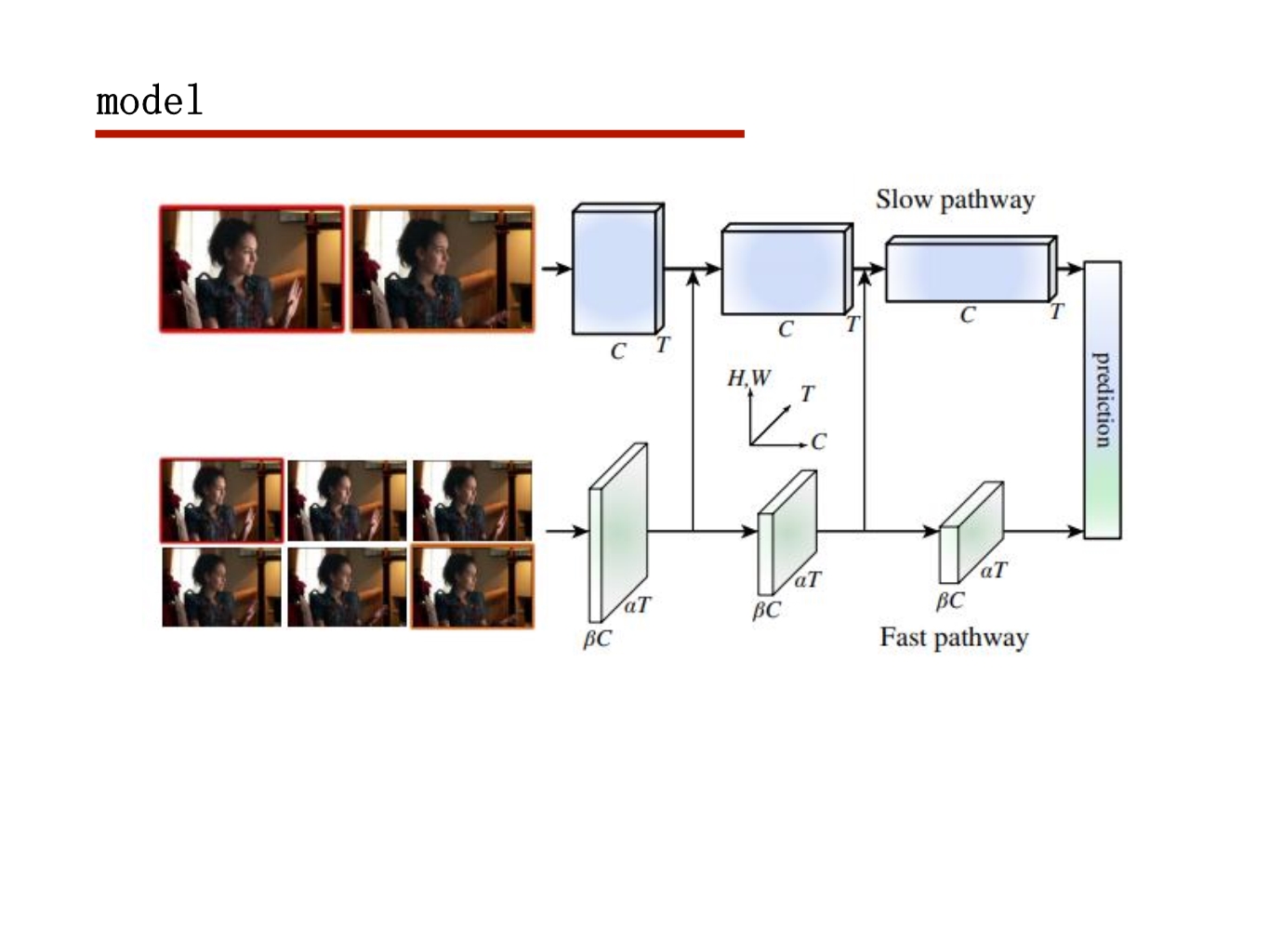
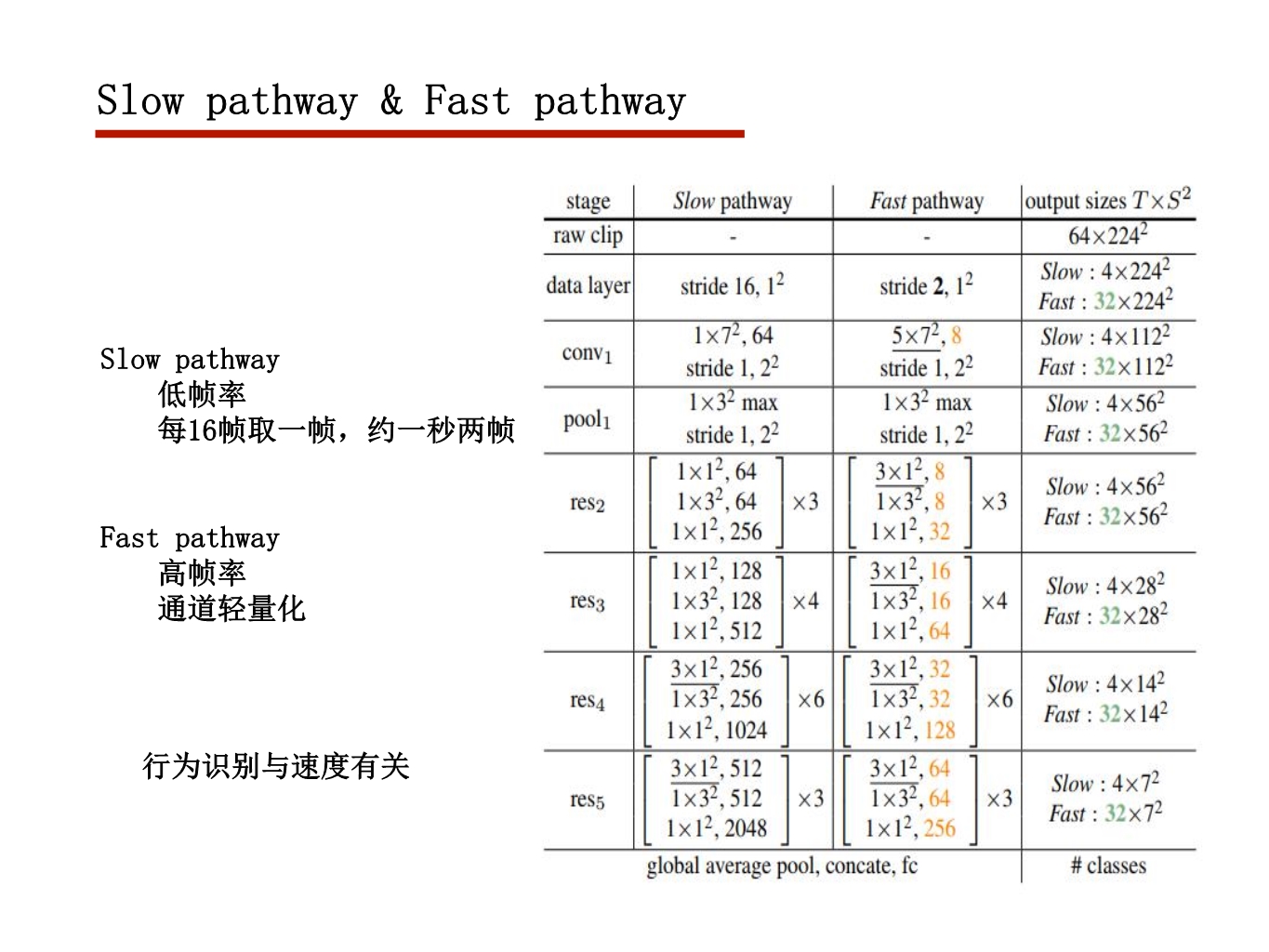
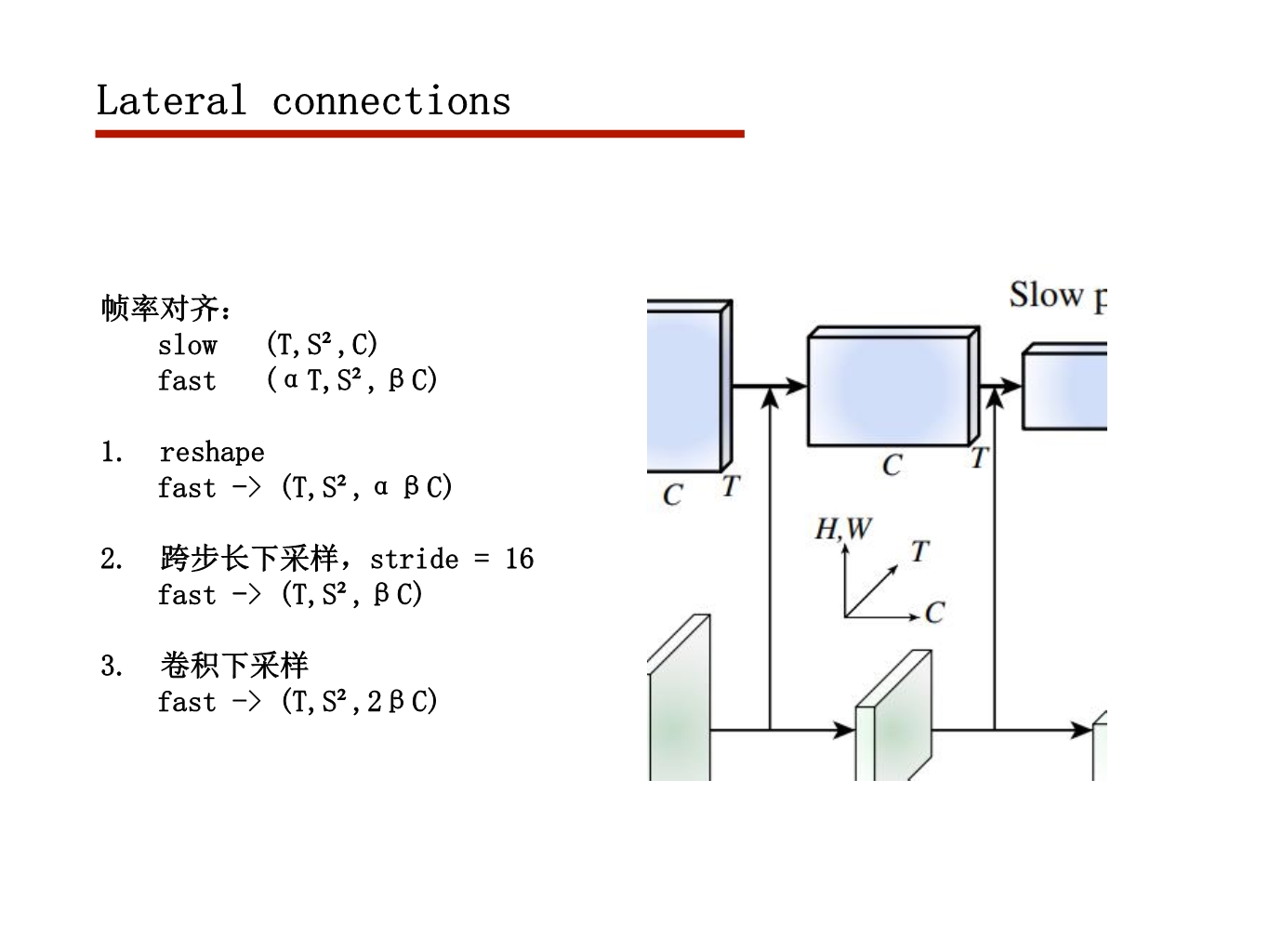
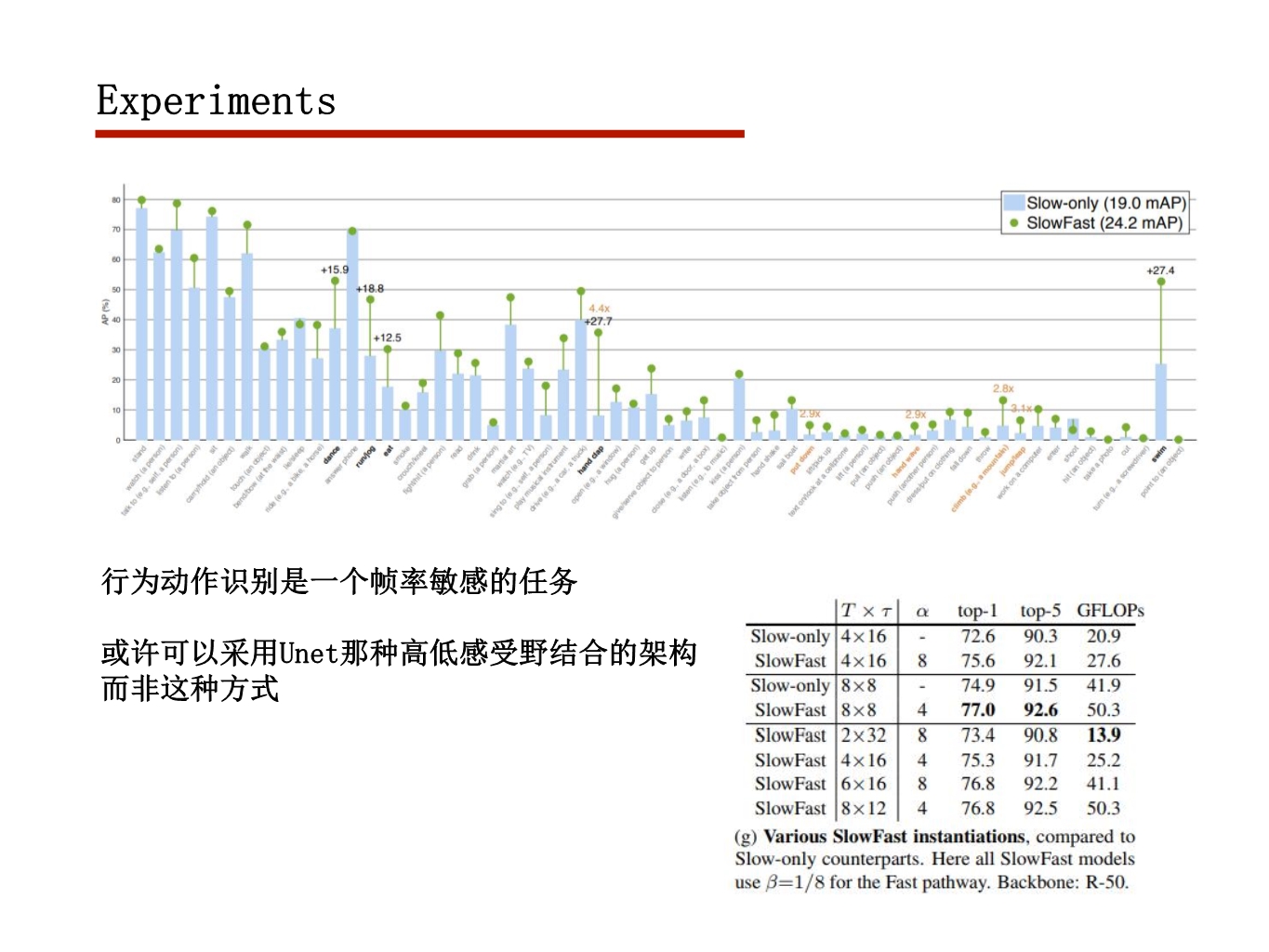
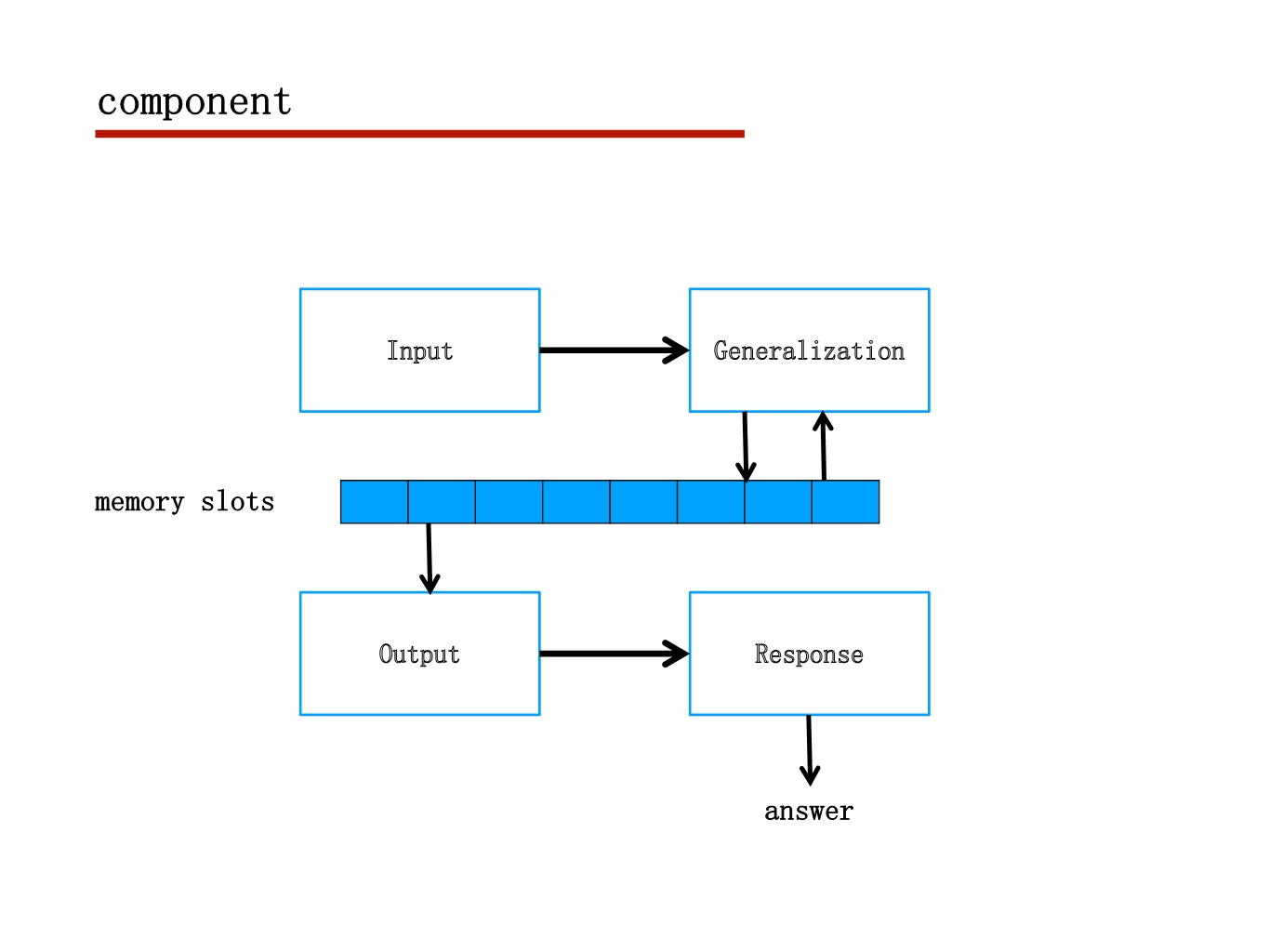
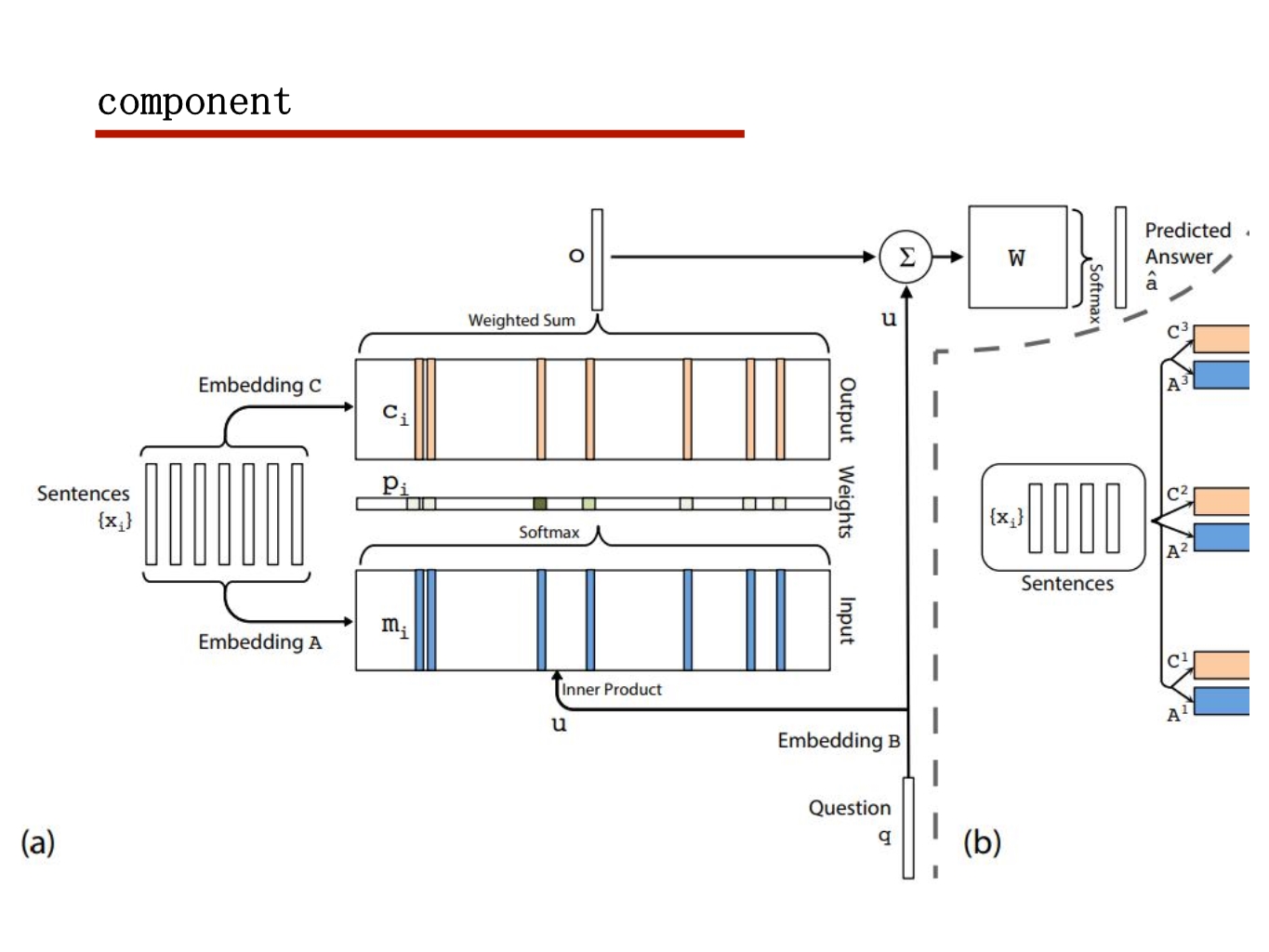
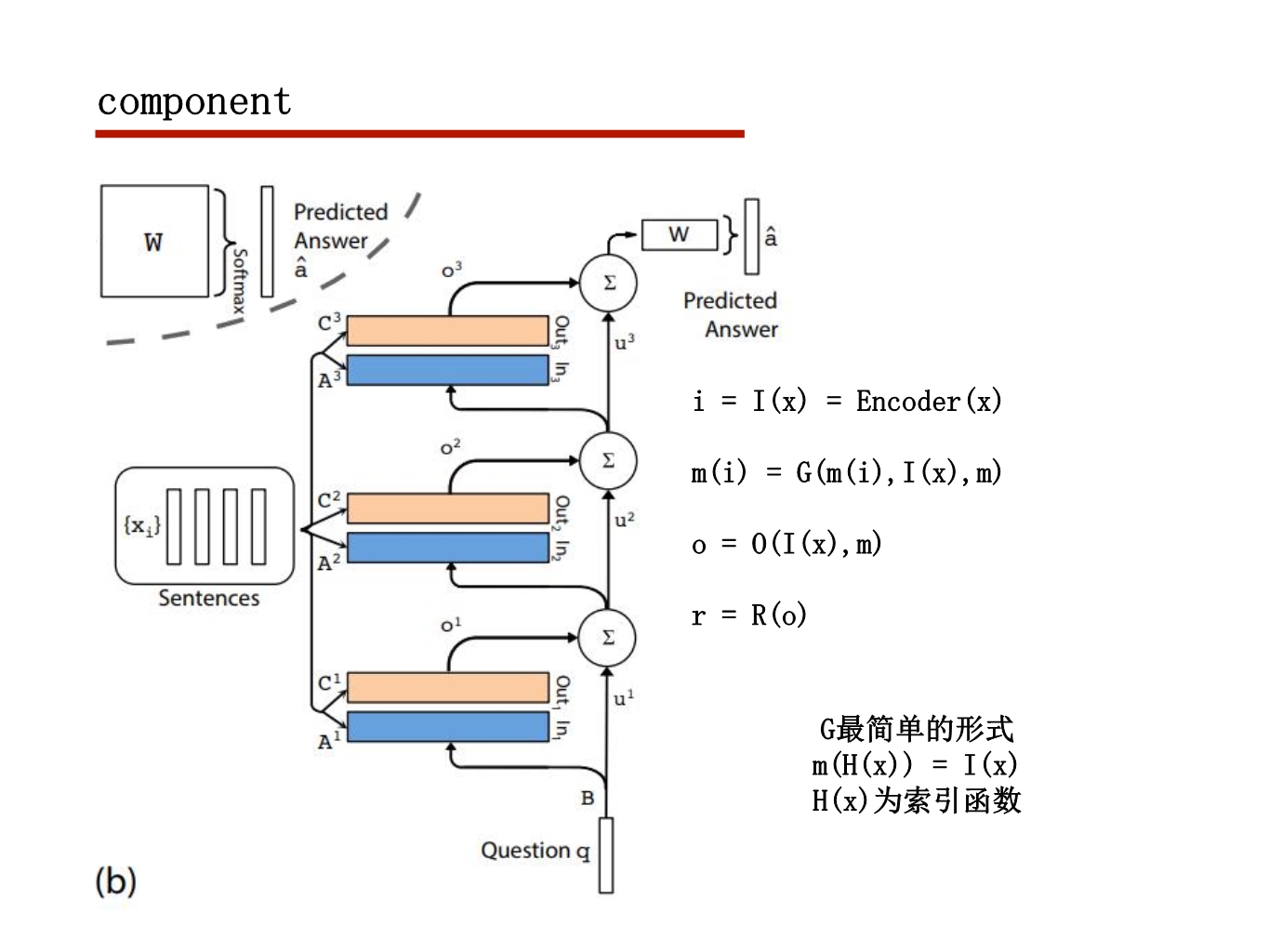
行为动作识别任务


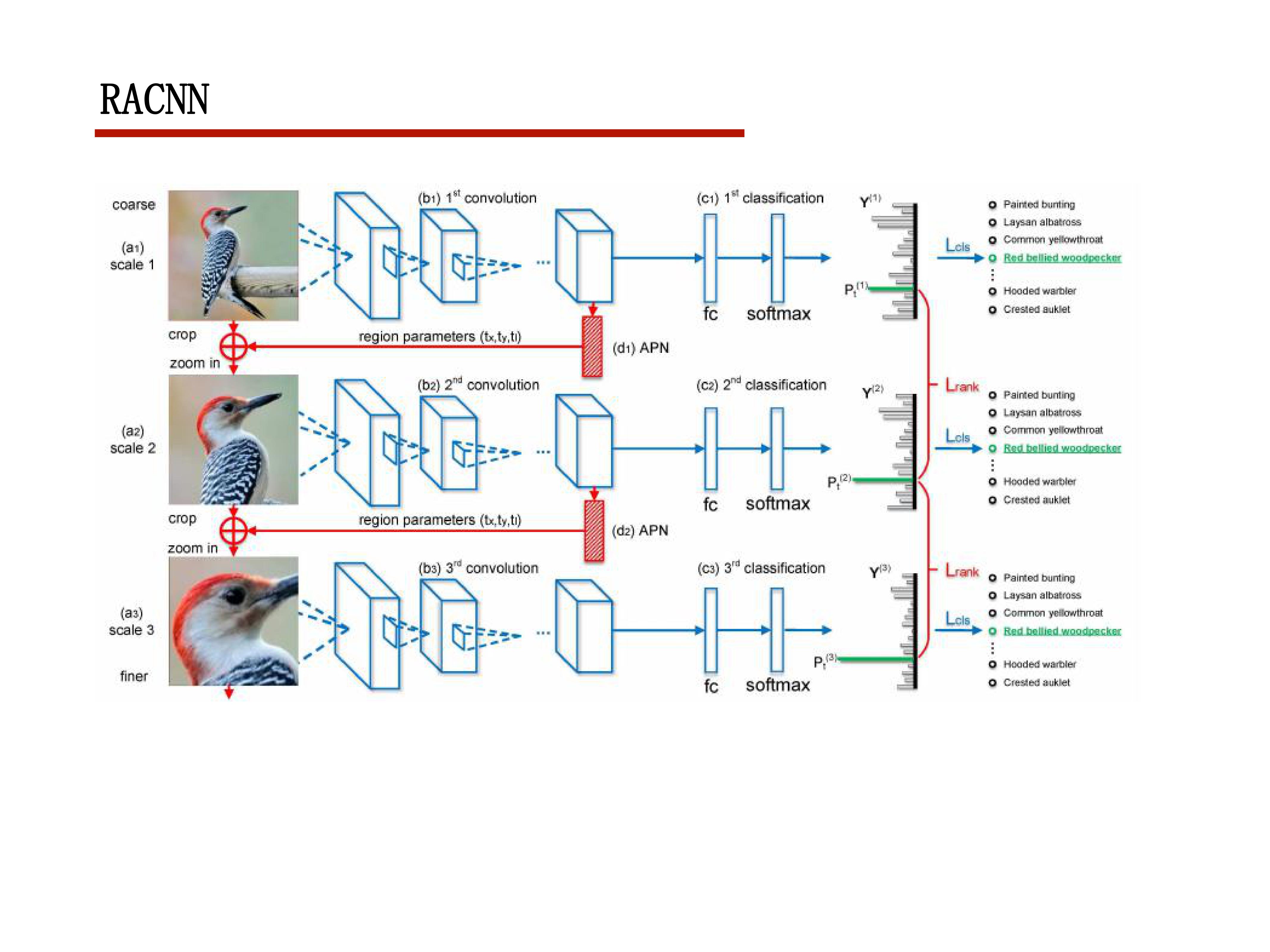
2017CVPR RACNN
这篇文章其实是篇比较简单的文章
但是其中有个梯度反传的细节很多博客都没纠清楚
文章里也没细讲
这篇文章主要就是利用弱监督定位去做细粒度分类
想法还是比较有意思的,上一次见到窗口定位的方式是在local attention
要弱监督定位需要把梯度传到坐标上,如果坐标进行取整则不能反传梯度
坐标的梯度更新是通过他设计的mask传回去的





之江视频问答1st比赛总结
由于PPT上都是图,直接发打字比较好
PPT那么多页其实也就几段字,哪有那么多东西讲
mp4关键帧I帧抽取,抽取I帧至40帧,不足则在I帧之间补足40帧
2017vqa冠军的模型 faster rcnn
(1) 抽取36个物体,受限于IO效率,物体和帧之间以帧为重
(2) attribute特征,把输出bbox的属性词作为特征,一是无io压力,二是视频物体种类变化小,可依据该事实通过频率提高该特征信噪比
无效模型 densecap : image caption + action location
本想用它解决动作类问题,无奈句子不方便通过频率筛选,提高特征质量,以及他本身效果不算特别好
外加句子关键词太少prior mask
各类question答案词表分布很不一致,如颜色类问题,数量类问题
很容易想到希望对每一类问题针对性处理,可通过用一个prior mask实现,将该类问题可能回答出的词标1,否则标0,
sigmoid激活后与之相乘,避免常识性错误,以及免去类间干扰(question类别)
如此实现了特征共享,但每类问题针对性处理,且可自由扩展类别数量
question类别用最易于区分的关键字作为类,如what color ,how many 以及or类问题的or两边的词很容易有下面的改进方法(我没去做,感兴趣试试)
(1) 以2中抽取的视频attribute作为视频关键信息,通过这个抽取视频先验词表改进prior mask
(2) 减小类内干扰,如深红,浅红,细粒度分类无论在nlp还是cv都是个较难的任务,
但是不用细粒度即可答对,干脆放弃细粒度分类
这个问题可以抽象为用尽可能少的答案覆盖该类问题所有答案问答框架
多问多答,可变长输入
问题不足五个重复补足- 免去冗余的五次io
- 带来上下文信息
劣势是偏固定的采样方式使他分数若不使用上下文信息会劣于一般训练方式
改进方法:用0补,重复会让特征信号加强,然后loss梯度权重加倍。。。
用0补的话是常量无信息,输出时可配合mask把梯度屏蔽掉
针对分镜问题的数据增强方案
找俩视频,各取一半帧数,时间轴拼接
问题的话随便取出5个
attribute各取频率最高的一半
一问一答,label直接取逻辑加其他数据增强
(1) 训练时抽来的40帧随机取16帧 (帧数取太少的话不会有效果的)
(2) 测试时隔帧各采16帧,做test aug模型
(1) 注意力使用MLB计算(其实啥注意力都差不多)
(2) 注意力集成机制:前几层question和video算出注意力权重后,各个问题生成的权重(16,1,1)取平均
与video(16,36,384)各帧相乘
(3) attribute 与 question直接算MLB加权平均
(4) encode用conv 11
用faster rcnn特征劣势是失去了空间局部依赖,又因此间接导致失去了物体级的时间局部依赖
rnn与cnn都不能用,采用self-attention+attention稀疏化解决跨时空依赖的想法
稀疏化方式 relu(w-(max(w)+min(w))/(1+λ)
经过调了半天λ,输出注意力矩阵后发现近乎为对角矩阵,退化为11conv,故直接用1*1conv
(6) video与question压成向量用co-attention(其实都差不多)
(7) 多问多答问答框架自带的上下文特征,其他question特征取平均与当前question拼接
(8) unit调到最小再调dropout(吐槽一下某人的0.95的dropout)
(9) 输入层bn + spatial dropout (bn在前,否则会有些shift)
分类层dropout,计算注意力前加spatial dropout
(10) focallossattention + loss 稀疏化(这部分我没用,分数不稳定,上限高下限低)
topk注意力,取权重前k名的取平均
loss稀疏化,loss最高的k个answer返回梯度,其他不反回
词表太小,loss稀疏化没效果,语言模型如word2vec这种词表近万或过万的有较大效果
可能物体仍然太少,所以不值得稀疏化
参数也不算特别好,经验上关键的地方动了一下,其他没管
以前不混天池
未来几个月可能在这边待一会儿
希望各位大佬发车的时候带上我
如上
2017ACL Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme
这篇文章内容本身其实蛮少的
但是意义还是较为重大的
整篇文章唯一的创新点大概在序列标注的标记模式
(1)-(2)-(3)
(1)内容使用BIES模式标记实体Begin, Inside, End,Single
(2)内容使用类别标记实体类别
(3)标记实体的在一对关系中的起始和终止位置
就近原则组合(2)相同,且(3)分别为1,2的实体
下面是模型部分
直接看图就好,没什么创新点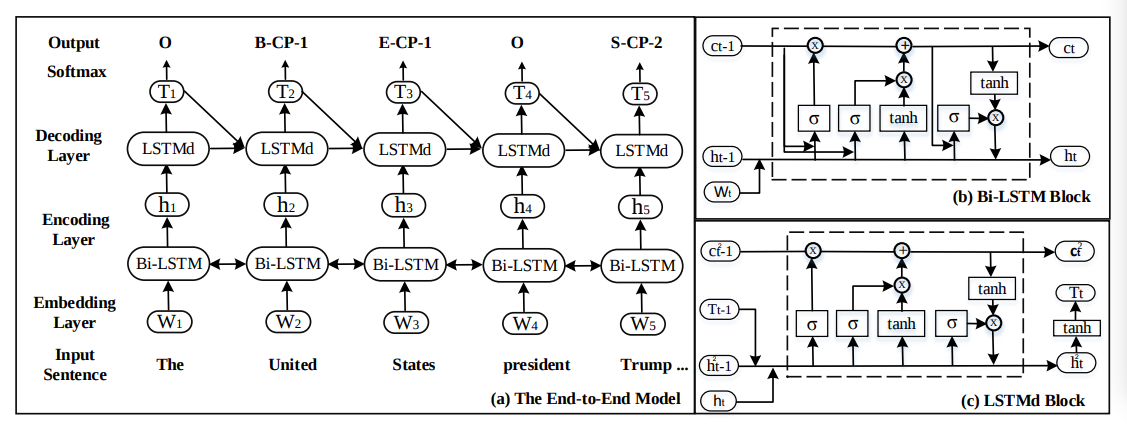
这是loss
就是负类正类权重不一样,也没什么好讲的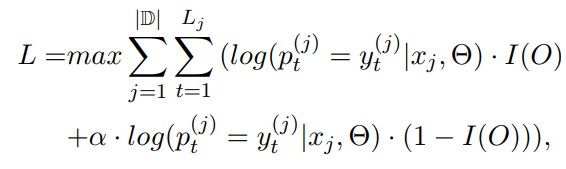
这种方式效果也较为不错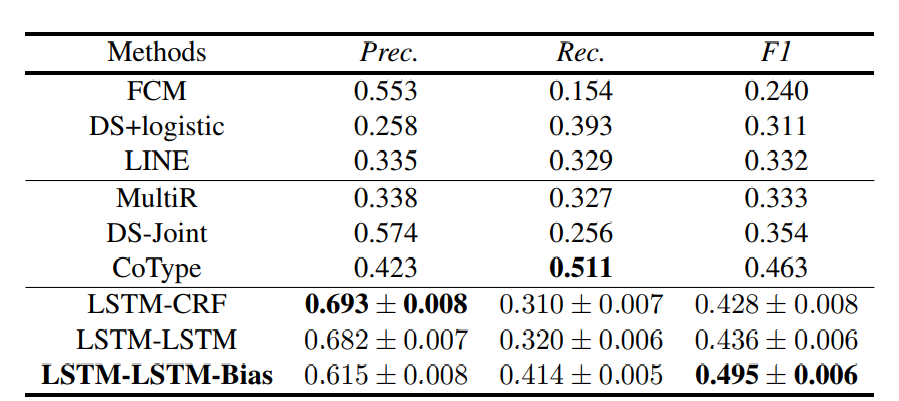
但是弊端也较为明显,对关系重叠问题解决不太好
解决方式也很简单,多分类改成多标签分类就好了
还有一个貌似对句子拆分要求较高。
讲讲我做序列标注任务的几点感受
对padding十分敏感
sota说是crf+lstm
其实应该是双层lstm+crf
后面太慢了不过可以用cudnn加速版配自己写的mask zero
同类对比CRF
很早之前看CRF一直都是一堆概率图
一堆公式,看的晕乎乎,最后也不知道怎么算如何用
后来几个月前看到苏神的博客才醍醐灌醒
然后这几天也一直在研究crf的源码
其实这个东西哪里有那么复杂
同类对比是个很好的理解方式
以序列标注为例子
首先我们看看直接以softmax建模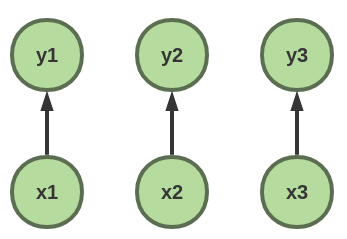
对序列的每个输出都进行softmax输出概率P(Yi|X)
整个序列出现概率为P(Y|X) = ∏i P(Yi|X)
该序列的loss为
loss = -Σi log(Yi|X)
而这种建模序列概率的方式没有考虑到序列标签的依赖关系
crf是考虑了这种依赖关系而对整个句子的概率进行建模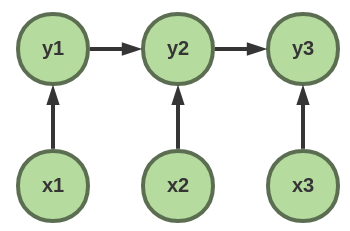
P(Y|X) = exp(h(y1;x)+g(y1,y2;x)+…+h(yn;x))/Z(x)
P(Y|X) = exp(Σi h(yi;x) + Σi g(yi,yi+1;x))/Z(x)
如此给句子打分就考虑到了句子间的近临依赖
loss = - log(P(Y|X))
其中h是之前rnn/cnn等的输出,而g是状态转移矩阵,可用自定义rnn实现
但是分子计算是完成了
分母的计算呢
这里用到dp即可计算得到
Zt+1(i) = ( Σj Zt(j) G(j|i) ) H(i|X)
Zt+1(i)意思是t+1时刻以i结尾的所有序列得分和
G(j|i)为exp(g(yi,yi+1;x))
H(i,X)为exp(h(yi;x))
那么还有一个问题,如何预测?
普通的对句子的所有输出进行softmax,直接argmax就好了
用crf的话就涉及到最长路径
这个直接用vibiter算法即可获得
IoU-Net 阅读笔记
好久没碰检测了
前段时间因为一些事情又focus了几天
今天做个IOU-Net的简短笔记
简单来说这篇文章主要是针对这样一个问题
检测的目的很明确,为了获得高质量的bounding box
然而在以前的做法当中是先通过一系列bounding box然后再经过筛选获得
筛选是以分类置信度为第一优先级
但是,分类置信度和bbox proposal质量存在相关性但非同步增减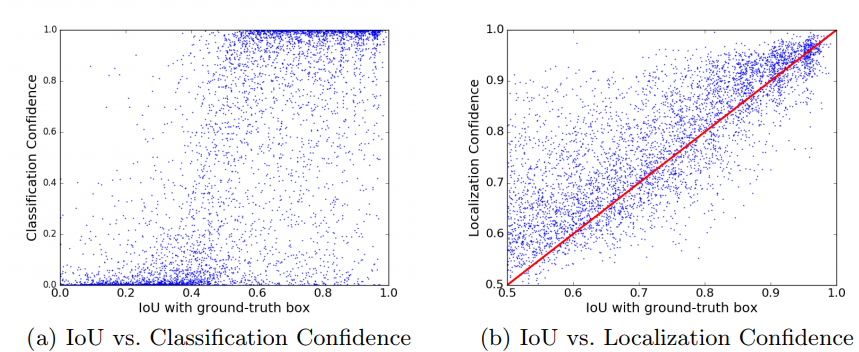
基于这些问题,这篇文章提出了以下策略
IoU predictor
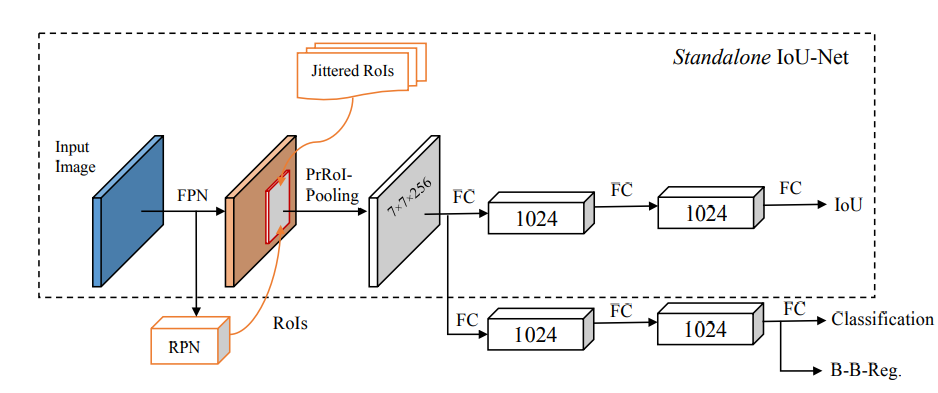
加入IoU预测分支,loss使用smooth L1
使用非RPN提供的proposals,而是ground truth加随机绕动得到Jittered RoIs
IoU-guided NMS

首先选出IoU最大的bbox
获得与该bbox重叠率大于某阈值的bbox集合
将该bbox的分类置信度更新为该集合内分类置信度的最大值
滤掉该集合内的bbox
如此循环…
Bounding box refinement as an optimization procedure
这部分也就长话短说
就是我们现在有一个IoU预测器,以及检测获得的bbox
将这些bbox输入,获得其IoU预测值,再通过梯度反向微调bbox
PrROI直接看公式吧
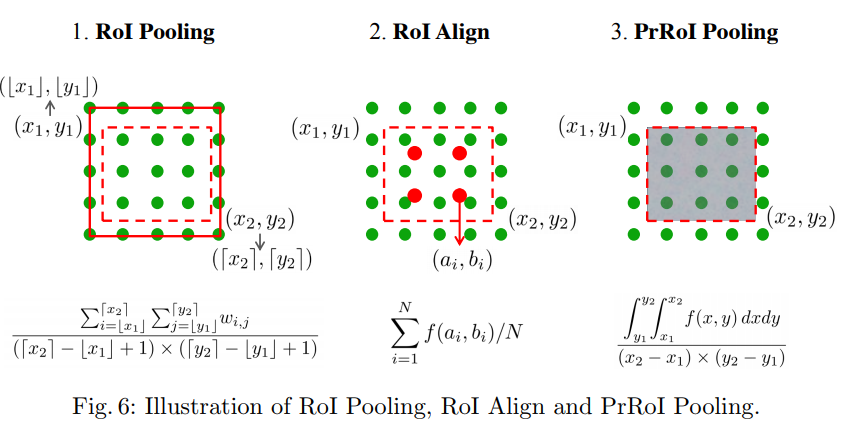
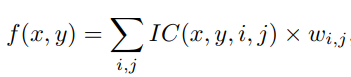
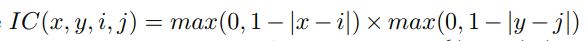
ROIPool -> ROIAlign 避免量化
ROIAlign -> PrROI 修补了ROIAlign不能由bin大小调整的缺陷
result
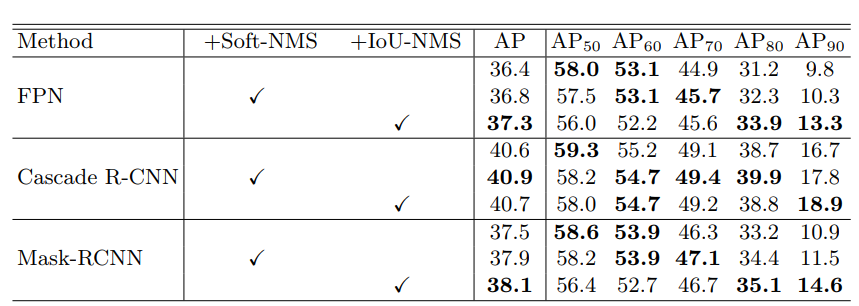
高IoU阈值时有较显著的提升
s2s learning as beam-search optimization
这周自己做的水报
16年的文章,感觉好像应用的并不多
然后文章里的loss缺陷也很明显..约束不足,感觉只适合微调
最近真的好忙啊…
争取下几周能搞点质量高的
反正先发上来








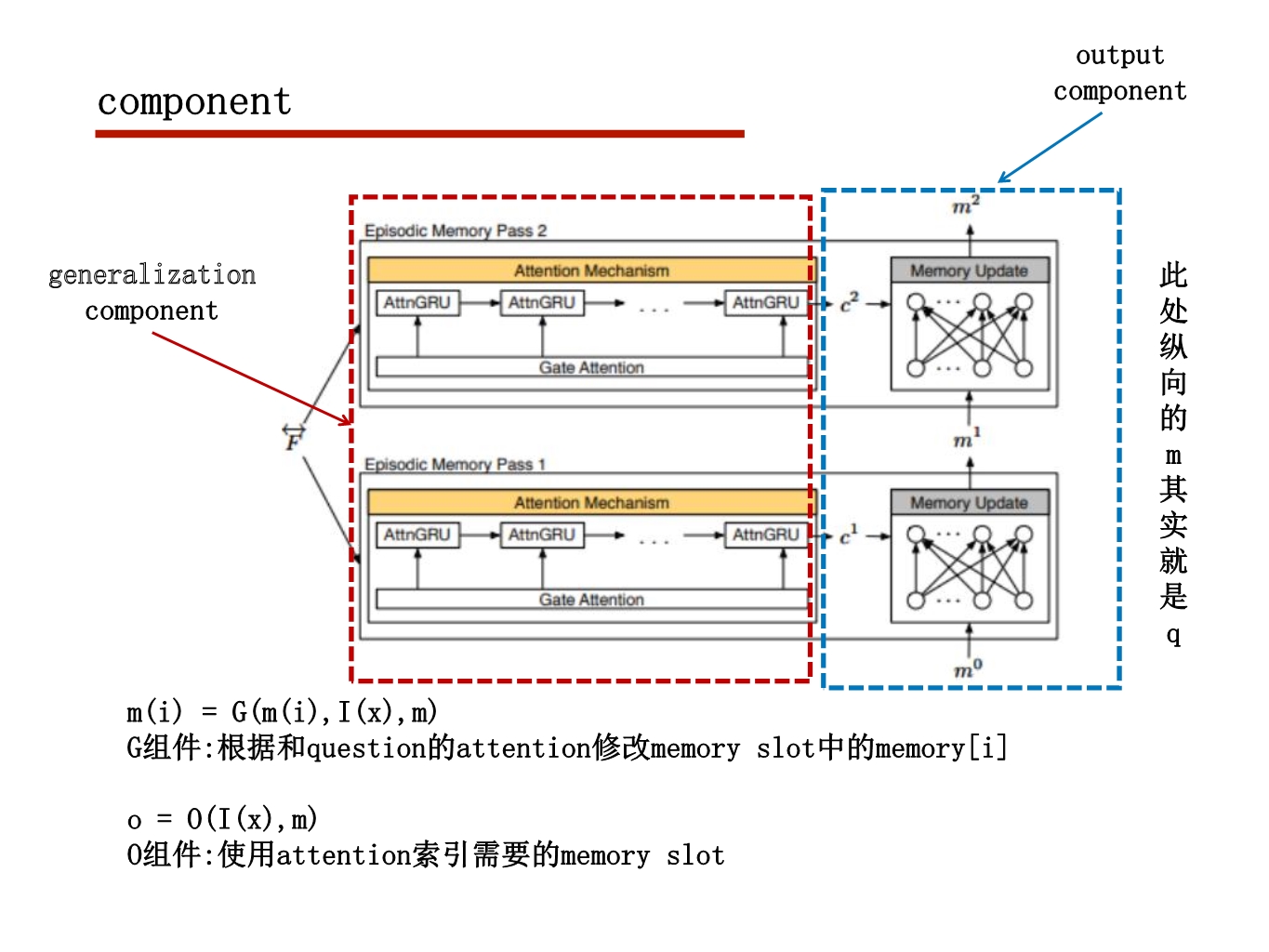

2018ECCV DaSiamRPN阅读笔记
原文链接
https://arxiv.org/pdf/1808.06048.pdf
这个模型是2018VOT实时比赛的冠军,VOT2018长时比赛的亚军
DaSiamRPN在普通跟踪的Accuracy指标和长时跟踪的Recall指标中均排名第一
这个模型是基于他们今年之前的一个模型Siamese RPN改进得到的模型
处理样本不均衡策略
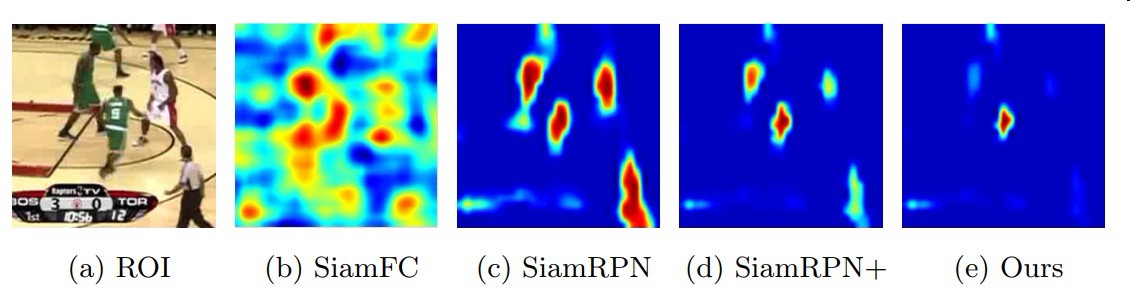
作者发现在跟踪过程中跟踪器对实例分类困难
而对前背景分类能力较强
而造成这个问题的原因他归因为跟踪过程中样本不均衡
正样本实例种类不够多模型泛化能力差
作者在训练过程中加入了如下所示的样本对进行离线训练
增量学习方式
公式如下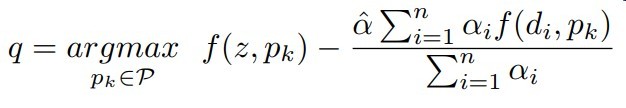
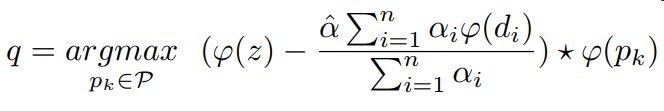
与模板帧的匹配分数 - 与干扰物的匹配分数作为最终分数
这些抗干扰物选择方式如下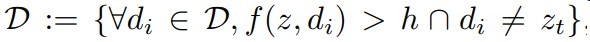
选择与模板帧相似度大于某个阈值的错误实例
再进行一般化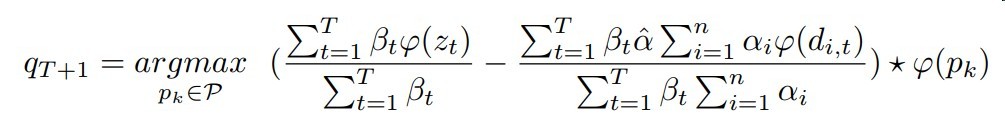
参数设置细节见论文
各组件收益

sparsemax
这篇文章主要是稀疏性的需求而提出了一个带有稀疏特性的归一化函数sparsemax
常见的有 sigmoid/tanh -> hard_sigmoid/hard_tanh
sparsemax在二维情况即为hard_sigmoid
我认为稀疏特性是attention以后十分重要的发展方向
目前大部分的soft attention都是基于softmax
这就带来了一个缺点,每个元素都会对结果产生影响
而hard attention又带了难以优化的问题
自然而然sparse attention是一个很好的发展方向
虽然本篇文章我应用效果并不怎样…
但是仍然感觉很有启发意义
本篇文章稀疏化的方式是通过一个阈值
再利用max函数屏蔽掉一部分权重
其中[x]+指代max(x,0)
该阈值的好处
- 介于min(z)与max(z)之间,保证能屏蔽一部分与留下一部分
- k的选择保证了主要成分的保留
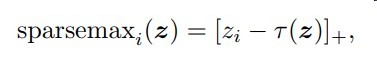
此函数需自定义梯度回传公式
梯度回传公式如下
其中S(z)为[z-r(z)]+中非0的部分
这个梯度公式意思很简单
即用到的部分回传梯度,没用到的部分梯度为0
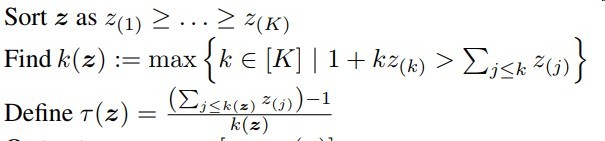
sparsemax应用场景
- attention归一化权重
- 多分类