最近为了在实习前集满GM的5金去参加了kaggle的语音比赛
参加语音比赛除了为了集金更是为了补足对语音方向基础的了解
以下源码部分来自kapre
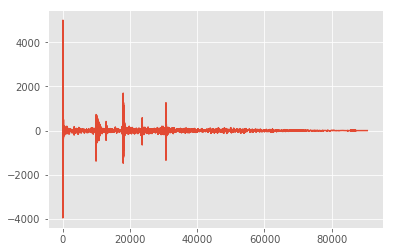
音频数据长啥样?
如图所示
这是一个单声道的语音数据
输入维度 (time_steps, channels)
channels表示声道个数
以下讨论都以单声道进行讨论,多声道的话同样的处理方式最后在通道轴拼接即可
什么是频谱图?
频谱图是音频信号的一种传统特征,效果不错
先上关键源码,再进行分析1
2
3
4
5
6
7
8
9
10
11x = input ## x -> (batch_size,time_steps,1,1)
subsample = (self.n_hop, 1)
output_real = K.conv2d(x, self.dft_real_kernels,
strides=subsample,
padding=self.padding,
data_format='channels_last')
output_imag = K.conv2d(x, self.dft_imag_kernels,
strides=subsample,
padding=self.padding,
data_format='channels_last')
output = output_real ** 2 + output_imag ** 2 ## output -> (batch_size,time_steps,1,freq)
总得来说,他是以卷积的方式扩展出了频率轴
会有人问:为什么是频率轴不是通道轴
因为这里的卷积是傅里叶变换的替代实现,这个轴的物理意义即频率。
操作如下:
- 音频数据分帧定帧长(即卷积的窗口大小)
- 各帧进行FFT后计算频域复数的模长(即能量)
- 然后通过帧移对各帧(卷积步长)对各帧进行FFT
- 以上从而将(time_steps,1)->(time_steps,freq)
由于FFT的频率是按序计算,所以音频数据在频率轴仍然有局部依赖
即可使用CNN或ConvLSTM1D之类的结构进行建模
上一张图吧
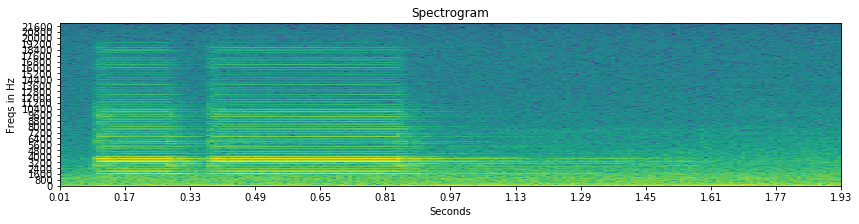
Melspectrogram
这个Mel频谱其实我也不太理解物理意义
但看源码十分简单,就是用一个矩阵对频谱图做线性变换
翻阅一些其他人的说法主要是考虑了人耳的声学结构
然后在尺度上做一些变换1
output = K.dot(power_spectrogram, self.freq2mel)
了解到这儿应该够我做这个任务了。。
毕竟就算理解了Mel频谱的滤波器设计方式我也大概率优化不好
最后
MFCC也不详述了,因为MFCC根据往年比赛方案以及相关总结都是说不适合nn
上面讲的特征都是可以e2e实现的,但是一旦设置成可训练效果极差。。。真是NB的手工特征