先附上原文链接,一篇18年4月份的文章,仍然是标准的bilstm+crf
Joint entity recognition and relation extraction as a multi-head selection problem
然后大图镇场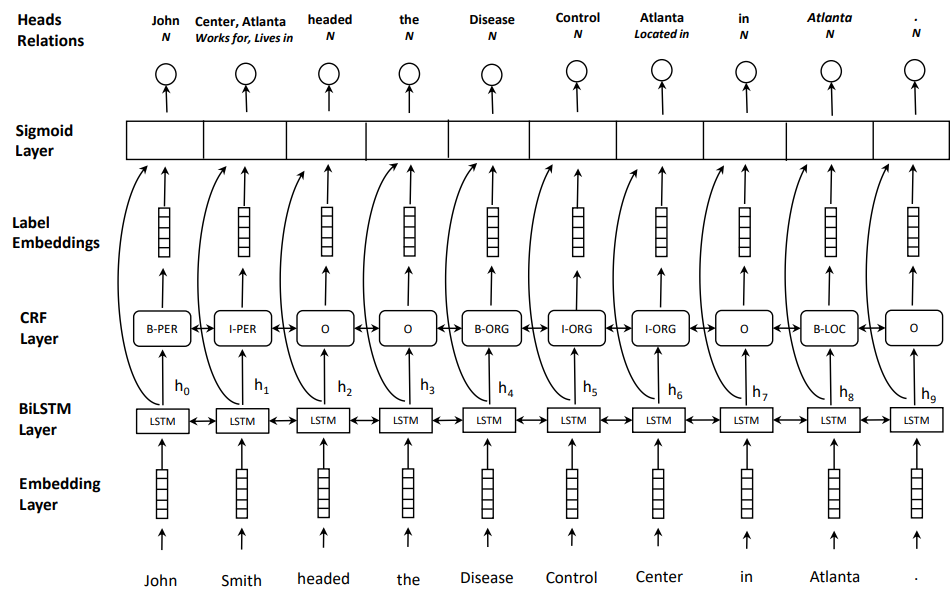
Joint model
底下三层序列标注的标准方式自然没啥好说的
emmm还是要说一下的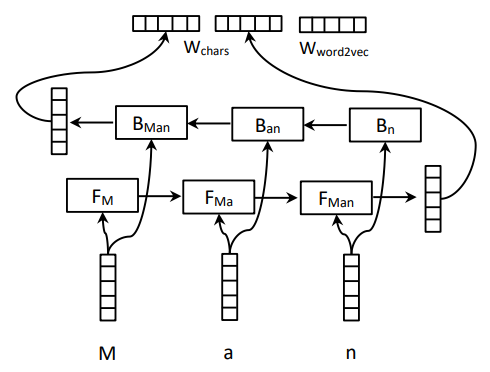
底部embedding layer
word level语义与bilstm 获得的char level语义拼接
不过也算常规操作
然后CRF获得序列得分进行优化
不过一个小细节说明一下,在第三层第四层的衔接处
CRF后面是不能接layer的,他后续使用维比特算法解码的序列标签也不能求梯度,如何实现呢?
- 框架中设置这里的不求梯度就好了
- 不过文章里貌似是训练时把正确label传进去,测试时用crf获得的结果去推断
Relation extraction as multi-head selection
接着是关系抽取部分
直接上公式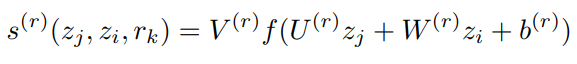
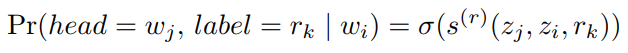
r是relation,z是word/char在lstm encoding后的向量
w是word/char
其实很简单,实体标签embedding信息和词经过lstm后的encoding信息
句子里的字两两计算关系类别得到一个N*N的矩阵,矩阵的每个元素都是某对字/词的关系分类结果
此处使用sigmoid激活,因为可能存在多种关系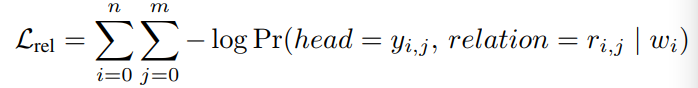
最后
感觉最后的关系分类还是可以试试别的而非sigmoid
得分矩阵的每一行都是有序列关系在里面的
例如第一行是第一个字和每个词是的关系得分
或许可以像序列标注一样套个概率图模型加强约束?
得分矩阵非每一个都是有效的
有些地方是否需要加个mask让他不要产生梯度影响训练?