文章链接 https://arxiv.org/pdf/1811.05181.pdf
核心思想
通过数据集的梯度分布去调节训练时权重
旨在降低label噪声影响和对hard example更好的学习
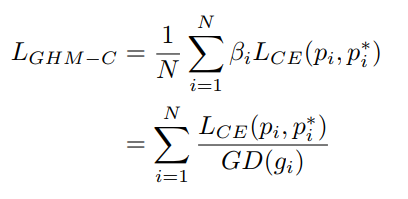
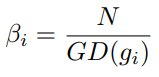
Gradient Density
意思就是密度越大的样本权重越低
密度大且loss大的样本认为是outlier
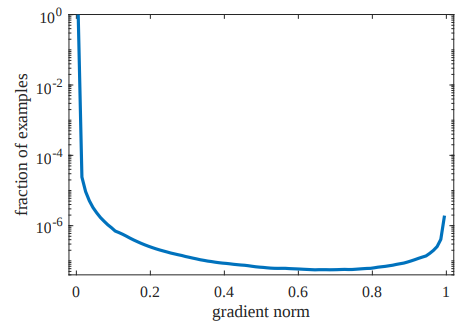
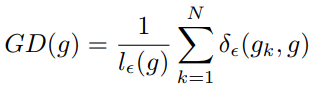
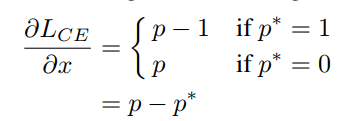
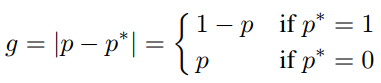
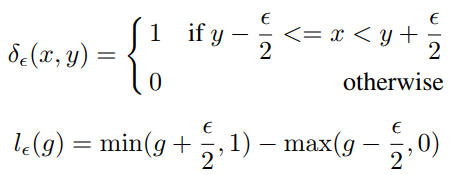
Unit Region Approximation
将梯度分区间段统计计算梯度密度
很简单的一个近似估计来降低算法时间复杂度
Exponential Moving Average
梯度密度是根据一个mini-batch的样本统计所得
通常情况下batch不能很好反应整个数据集的分布情况
梯度密度变化十分不稳定
通过滑动平均让这个变化变得更加smooth