Pointer Networks
https://arxiv.org/pdf/1506.03134.pdf
如上,其实就是直接把注意力权重的结果输出为最后结果了
即在原序列中抽样
旨在解决凸包和旅行商等类似问题
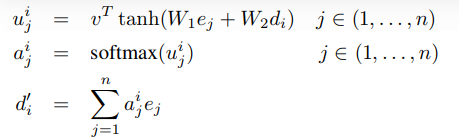
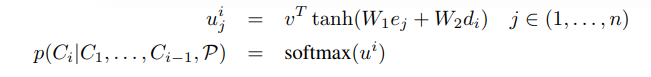
Copying Mechanism
https://arxiv.org/pdf/1603.06393.pdf
理解这个我们首先看个使用场景即如下

本文旨在解决oov和低频词版本
让模型学会适当从历史信息中copy文本
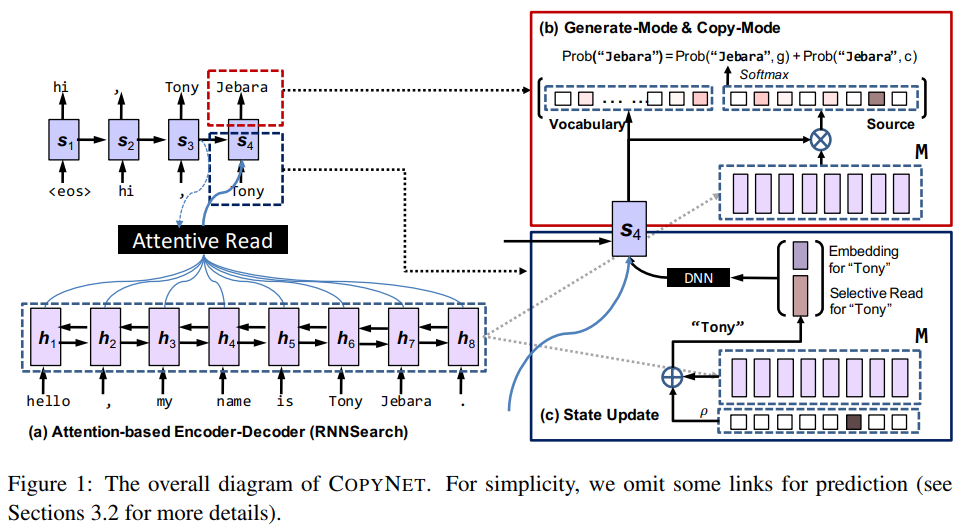
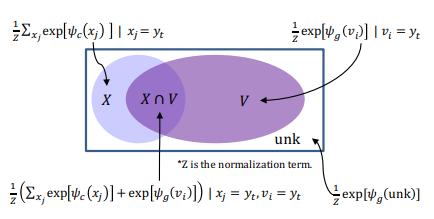
模型即上图
首先看模型的输入输出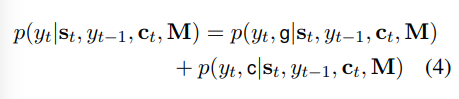
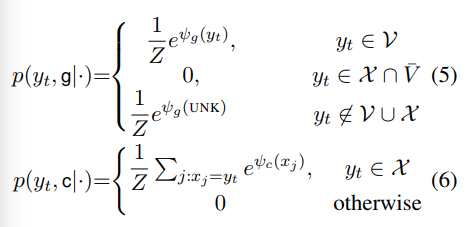
其中ct是当前状态对输入序列的注意力加权后的输出向量
M是输入序列的隐藏态h1 to ht
其中st = f(yt-1,st-1,c)是decoder的隐藏态
这里多加了一个输入,即从M中获得
如下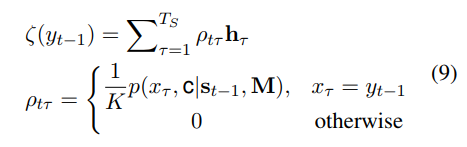
将yt-1在输入中多次出现的词考虑进来
整体来讲模型给那些 不曾在字典中出现过但又在输入中出现过的词 一个输出口
让模型在没能很好学习rare word和oov的语义的情况下能具备一些复制能力
Coverage Mechanism
Get To The Point: Summarization with Pointer-Generator Networks
https://arxiv.org/pdf/1704.04368.pdf
总得来讲
首先维护了在历史状态下decoder时输出的attention权重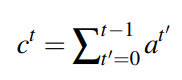
将其作为特征输入,用于计算当前attention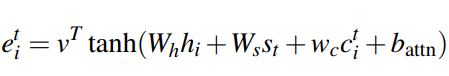
然后对于那些重复出现过高权重的词,给予适当惩罚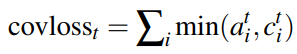
目的应该是希望模型不要老出现重复词