很早之前看CRF一直都是一堆概率图
一堆公式,看的晕乎乎,最后也不知道怎么算如何用
后来几个月前看到苏神的博客才醍醐灌醒
然后这几天也一直在研究crf的源码
其实这个东西哪里有那么复杂
同类对比是个很好的理解方式
以序列标注为例子
首先我们看看直接以softmax建模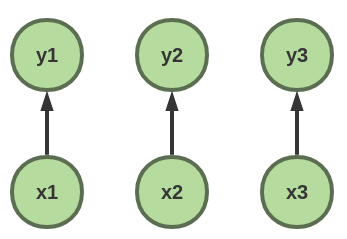
对序列的每个输出都进行softmax输出概率P(Yi|X)
整个序列出现概率为P(Y|X) = ∏i P(Yi|X)
该序列的loss为
loss = -Σi log(Yi|X)
而这种建模序列概率的方式没有考虑到序列标签的依赖关系
crf是考虑了这种依赖关系而对整个句子的概率进行建模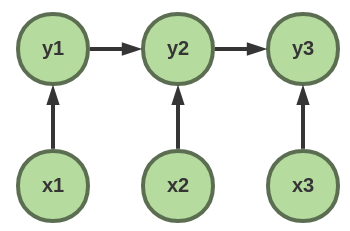
P(Y|X) = exp(h(y1;x)+g(y1,y2;x)+…+h(yn;x))/Z(x)
P(Y|X) = exp(Σi h(yi;x) + Σi g(yi,yi+1;x))/Z(x)
如此给句子打分就考虑到了句子间的近临依赖
loss = - log(P(Y|X))
其中h是之前rnn/cnn等的输出,而g是状态转移矩阵,可用自定义rnn实现
但是分子计算是完成了
分母的计算呢
这里用到dp即可计算得到
Zt+1(i) = ( Σj Zt(j) G(j|i) ) H(i|X)
Zt+1(i)意思是t+1时刻以i结尾的所有序列得分和
G(j|i)为exp(g(yi,yi+1;x))
H(i,X)为exp(h(yi;x))
那么还有一个问题,如何预测?
普通的对句子的所有输出进行softmax,直接argmax就好了
用crf的话就涉及到最长路径
这个直接用vibiter算法即可获得