原文链接
https://arxiv.org/pdf/1808.06048.pdf
这个模型是2018VOT实时比赛的冠军,VOT2018长时比赛的亚军
DaSiamRPN在普通跟踪的Accuracy指标和长时跟踪的Recall指标中均排名第一
这个模型是基于他们今年之前的一个模型Siamese RPN改进得到的模型
处理样本不均衡策略
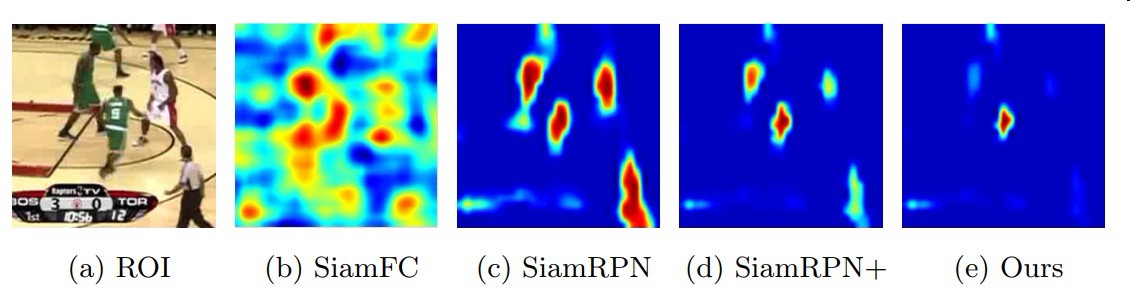
作者发现在跟踪过程中跟踪器对实例分类困难
而对前背景分类能力较强
而造成这个问题的原因他归因为跟踪过程中样本不均衡
正样本实例种类不够多模型泛化能力差
作者在训练过程中加入了如下所示的样本对进行离线训练
增量学习方式
公式如下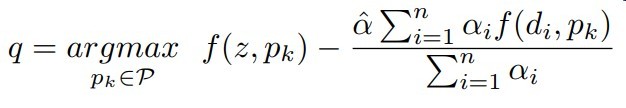
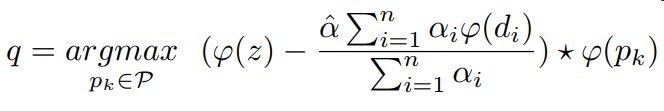
与模板帧的匹配分数 - 与干扰物的匹配分数作为最终分数
这些抗干扰物选择方式如下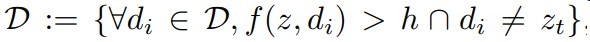
选择与模板帧相似度大于某个阈值的错误实例
再进行一般化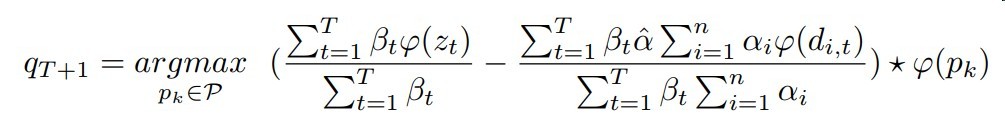
参数设置细节见论文
各组件收益
