这篇文章本身是用于seq2seq任务的
其中亮点提出了一个Multi-head attention具有相当的启发意义
attention function
给定一个query
再给定一组(key,value)对,value可以理解为某个事物的具体信息,key为其关键信息
attention机制就是给出一组权重,使得模型对value的各个部分的关注度不同
这个关注度由query和key决定
很基本的想法就是和query越相关,权重越大
这里涉及到一个度量函数,常用的有余弦相似度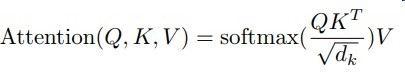
Q与K中的各个关键字做相似度计算,再进行权重归一化,对V进行加权求和获得最终内容
dk 是关键字的维度
获得权重后对value进行加权
大部分情况下key=value
个人认为当value维度过高时才需要关键信息的提取,这时才会有key和value的不同
当key=value=query时,就是self-attention机制
Multi-Head Attention

首先用几个线性变换W将query,key,value映射到多个空间
再对他们通过注意力函数提取value的高质量信息
然后用h组线性变换W,进行拼接就得到了multi-head
Transformer
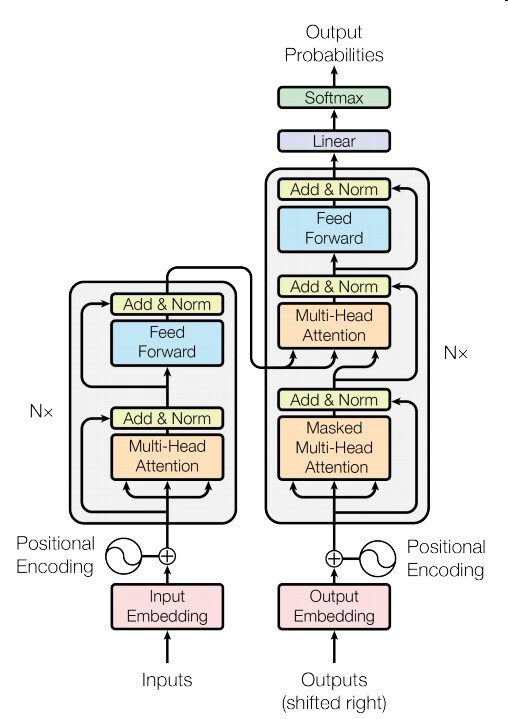
如上便是他的模型结构
左边是编码器,右边是解码器
Encoder
这个编码器由N=6个相同的组件堆叠而成
一个组件由两个子层组成
编码器的multi-head attention 是self-attention
Add & Norm是指残差连接和layer规范化
Feed Forward是指
FFN(x) = max(0,W1+b1)W2+b2
x是词向量
这就相当于两层kernel size = 1的卷积
或者时间步上共享权重的全连接层
Decoder
这个编码器由N=6个相同的组件堆叠而成
一个组件由两个子层组成
编码器的multi-head attention 是self-attention
Add & Norm是指残差连接和layer规范化
Feed Forward是指
FFN(x) = max(0,W1+b1)W2+b2
x是词向量
这就相当于两层kernel size = 1的卷积
或者时间步上共享权重的全连接层
output embedding
将上一时刻的预测作为当前输入
seq2seq的常用trick
position embedding
由于没有使用conv和rnn所以缺失位置信息
于是使用了一系列位置编码
其实看不大懂这个东西为啥work = =
见图
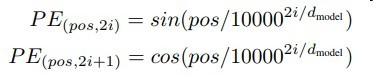
对于一个输入的句子矩阵(句长,词向量维度)
和他进行信息结合的是position以上述编码方式生成
i是第几个维度,pos是位置,时间轴
dmodel是词向量的维度
原本解释说这是因为PEpos+k可以表示为PEpos的线性函数
finally
这篇文章算是粗读
只理清了模型的推导
里面的参数设置和模型训练的具体细节没去纠
这篇文章对attention机制做了一个很好描述