模型结构
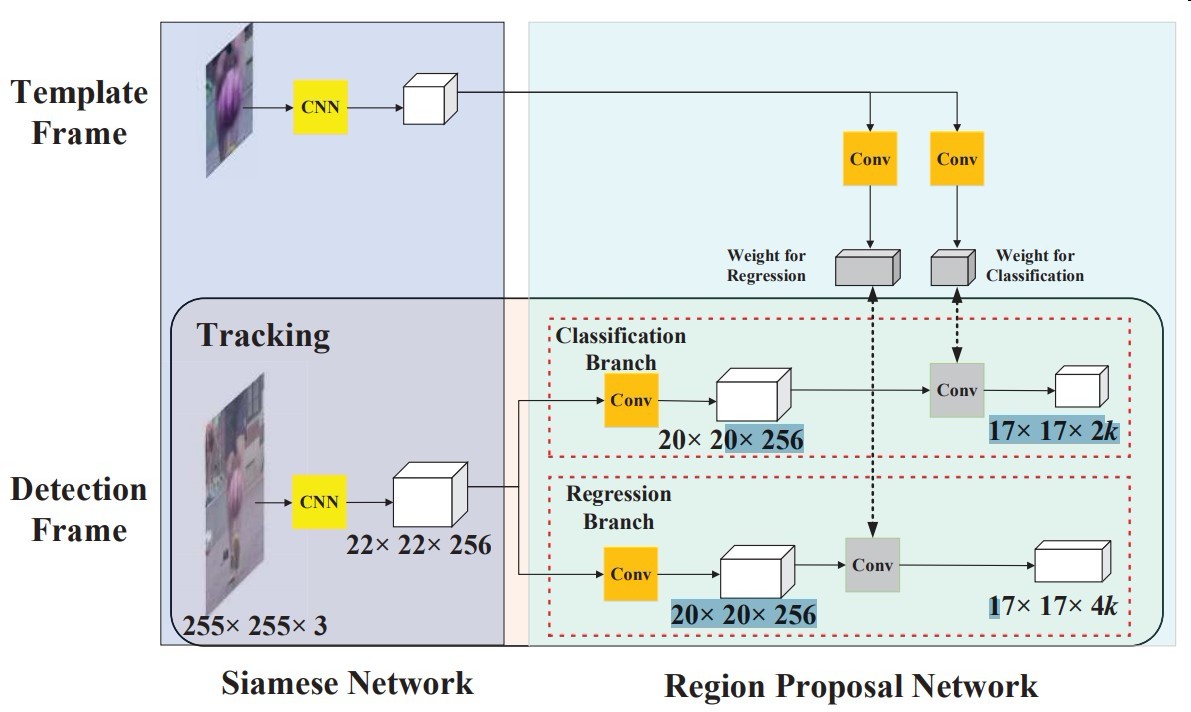
Siamese FC
使用AlexNet去掉conv2和conv4
所有卷积不使用padding
Region Proposal Network
其实看过faster rcnn 和 siamese fc还是一下子就能理明白的
- 模板帧用卷积抽成4×4×(2k×256)个代表k个anchor+前背景分类
- 模板帧用卷积抽成4×4×(4k×256)个代表k个anchor+坐标回归
然后模板帧的特征图与检测帧的做相关运算进行匹配
其中anchor比例为[0.33,0.5,1,2,3]
其中回归分支的需要,一些仿射变换用于做数据增强
然后proposed至少筛选16个正例,总共64个样本
正例IoU阈值为0.6,负例为0.3
然后loss照搬faster rcnn
one-shot detection
检测应用到追踪即为one-shot detection问题
推断
模板帧在第一帧推断后就不再更新了
- 第一帧的特征更鲁棒
- 速度快,nn慢就是因为要迭代bp
所以这需要大量的数据进行预训练获得通用化的特征
proposal selection
- 不选取中心位置离当帧超过七个像素的anchor
- 给模型的分类置信度加penalty,其中k是超参,r和s分别代表了尺寸和面积,衰减尺度面积变化过大的anchor
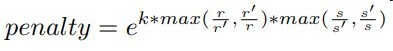
- 选K个分类置信度最高的,进行NMS抑制
- 最终尺度选定后使用线性插值进行平滑改变
other details
使用VID和Youtube-BB数据进行离线训练
每次训练模板帧和检测帧之间的时间间隔不超过100帧