前言
最近忽然发现lightgbm中有个梯度优化的loss
以前一直好奇树模型如何对auc进行优化
于是查了一下,作此博文
AUC在梯度树与DNN中优化的不同之处
之前我在文章https://qrfaction.github.io/2018/04/02/end2endAUC/简述了DNN对AUC的优化方式
基本就是用一个度量函数将AUC公式中不可微的部分进行平滑
然而在梯度树中这带来了困难
见下图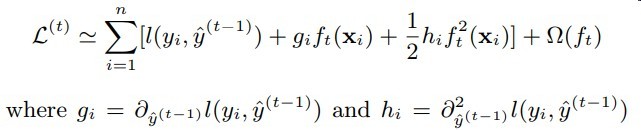
可知梯度树在计算梯度时主要获得的是针对每个样本的梯度信息
而原先在DNN中的AUC是无需将梯度细粒度到每个样本
只要有一个loss信息回传就OK了
可见原先的方式不再适用
Learning to rank 之 LambdaMART
MART其实就是GBDT(他名字很多诶)
这个方法其实是将rankLoss的梯度信息作为模型中的label y
即定义了模型的预测score的分数上升方向
首先定义一个rankLoss,其中si , sj是模型输出的score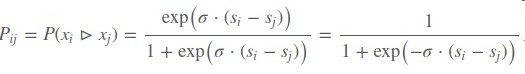
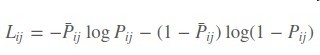
在对si求偏导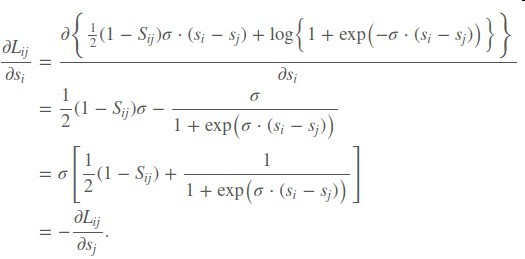
于是得到了一个si的上升/下降方向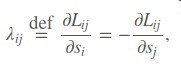
再令有序对(i,j)的排序label Sij = 1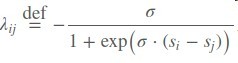
最后再将λi作为sample i的label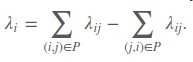
从而实现了树模型的Learning to rank
但这个我感觉应该对auc直接优化有很大帮助
因为毕竟auc本身也是一种基于排序的指标
但是否具有一致性就不清楚了
不过尝试了一下lightgbm中的lambda mart 训练速度超级慢…懒得试了