高性能CUDA应用设计与开发第五章阅读笔记
GPU存储器层次结构
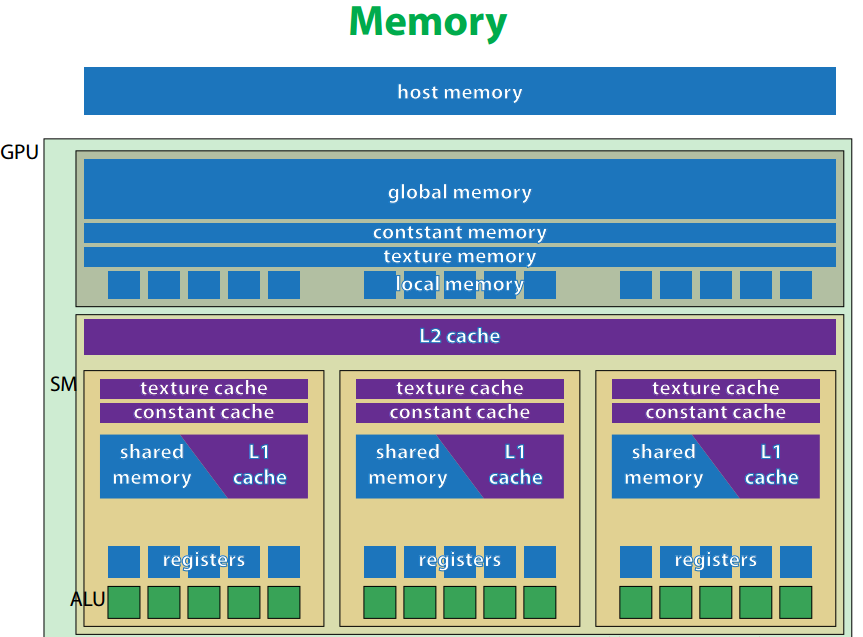
在GPU高速计算的过程中,GPU的性能极大受限于存储器的带宽
只有流多处理器的寄存器带宽满足流多处理器全速运转需求
不同类型GPU存储器的带宽如下
寄存器 约8T/s
共享内存 约1.6T/s
全局内存 约而0.1 - 0.2T/s
内存映射 约0.01T/s (主机内存映射到GPU显存)
实现程序的高性能必须在流多处理器内实现数据重用
因为经常访问的数据会被放入高速缓存之中
从而减少了从全局内存中读取数据的次数
L2缓存
- 由图知由各SM共享
- L2缓存采用LRU(least recently used)调度方式
- 由L2缓存调度方式可知,L2对非规则内存的访问具有良好的加速效果
- 所有数据的加载与存储都经过L2缓存(包括GPU与CPU之间的数据互传)
所以GPU与CPU之间的数据传输会影响缓存命中率与程序性能
L1缓存
- L1缓存基于空间重用而非像L2的时间
- L1缓存并不影响全局内存的写操作,这些操作会越过L1
- L1缓存用于两种作用
1.动态缓存
(1)记录线程的局部数据结构,如线程栈(栈最多占用1KB的内存)
(2)局域内存(用于存放从寄存器溢出的局部数据)
2.用于共享内存 - 广播数据
condition1: 一致访问 (同一个 线程块 内的线程均访问 同一地址)
condition2: 若使用的指针是const类型的
编译器将会识别出一致访问并生成LDU指令访问L1缓存,实现数据广播
局域内存
对自动变量的操作会访问到局域内存
所谓自动变量就是设备端代码中申请的,不包含device,shared,constant限定符的变量
通常自动变量会存放于寄存器中,但以下情况除外
- 编译器无法通过常量索引元素的数组
- 体积较大,导致寄存器资源消耗过多的数组或结构体
- 寄存器溢出
- 全局内存和L1缓存都有用做局域内存的部分
共享内存
bank冲突
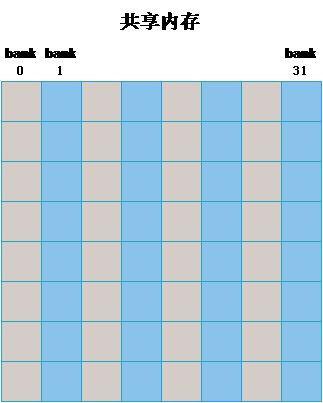
如图,当申请一块共享内存时,共享内存会被组织成32/16个bank(早期的GPU是16个)
不同的线程访问同一个bank会产生bank冲突,会被串行执行
早期double双精度数据也会引起bank冲突,因为他是分成两个32位数据放于共享内存中
在共享内存中填充空数据,可以避免bank冲突
如 __share__ tile[32][33]
这样即可使得一个warp访问同一列数据时发生错位,使得避免了bank冲突
共享内存的多播能力
若一个wrap内的多个线程同时访问同一个字,则硬件上只产生一次共享内存的读取操作
线程通信的注意事项
若共享内存用于线程块内的wrap通信,则共享内存声明时必须使用volatile前缀
避免误读缓存数据带来的错误 (否则,如数据被缓存到寄存器中,将读入旧数据)
常量内存
- 只有64KB,使用专用的常量缓存(per-SM)
- 具有数据广播能力
- 线程间并发访问常量内存不同地址时,采用串行执行
L1的一致访问其实也可以多播,不过当数据过多时,广播数据或许会被挤出缓存
这时候常量内存仍可利用
纹理内存
- 纹理内存驻留在显存中,并且使用一个只读cache(per-SM),访问显存数据需经过cache
- 当访问一个数据时,该数据的周围局部数据也会被加载到缓存中,这对数据访问具有局部相关性的模式具有加速效果
- 每个流多处理器仅含8KB缓存空间
- 具有一定数据存储能力,高效拆解和广播数据
- 当数据的访问发生越界时,支持各种插值算法处理越界数据 (这个是指卷积/滤波时发生矩阵越界访问?)
全局内存
全局内存的读取方式
- 缓存读取
内存逻辑首先从L1缓存中寻找数据,接着是L2缓存,若都没找到再从全局内存读取
全局内存的读取粒度其中一次读取128字节
这个应该是考虑到减少IO请求的次数,可能存在冗余读取的情况
这个时候内存对齐是十分重要的东西 (cudaMalloc申请的空间保证了至少256字节的对齐) - 非缓存读取
当读取大量数据且又不存在于连续地址时,建议使用nvcc的命令行参数 -Xptxas-dlcm=gc关闭L1缓存
这时SM不会从L1中寻找数据,全局内存的读取粒度由128变为32减少冗余读取
内存对齐与冗余读取详细请看该博客
https://blog.csdn.net/qq_17239003/article/details/79038333