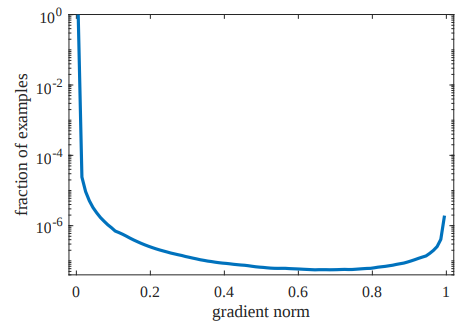
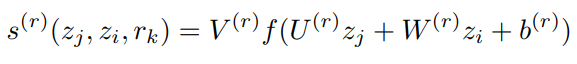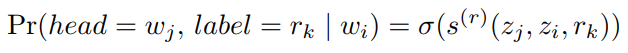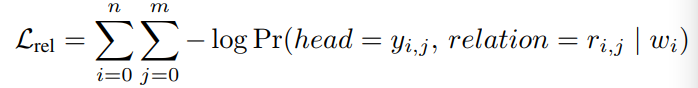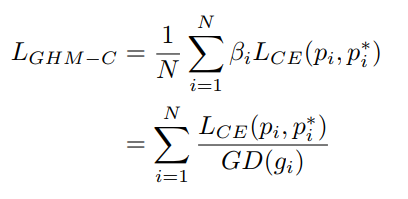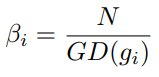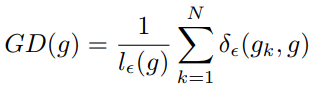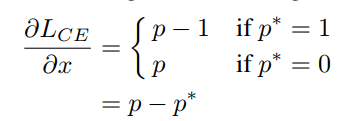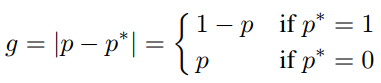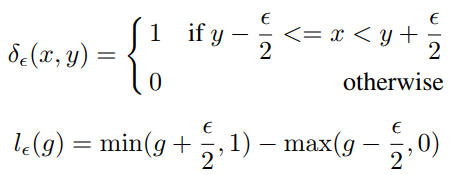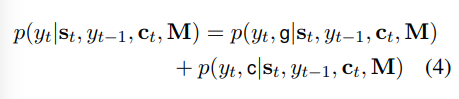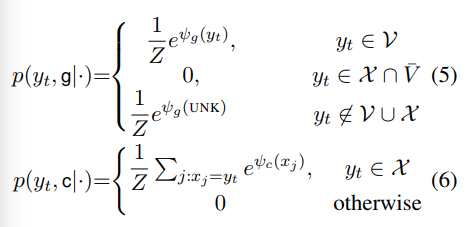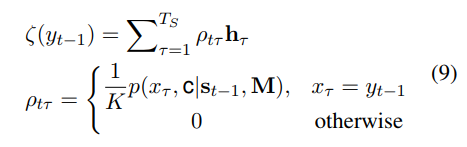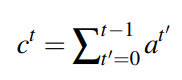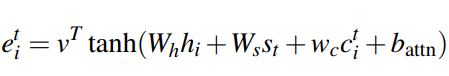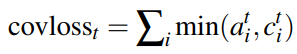最近频频在论文中看到计算当前样本的对抗样本作为正则项去训练模型
抱着好奇心这个东西究竟有多少收益,在audio tagging的比赛里尝试了一下
结论是成本太高,收益较小,很鸡肋
成本在于一个batch里每个样本都要计算对抗样本 <=> 调试时间和需求显存加倍 。。。
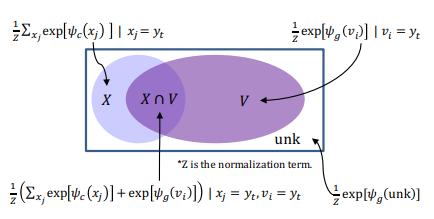
就是bs加了个倍,反正在audio tagging里太浪费了,这么多显存干啥不好。。
对抗样本的介绍下面一张图带过了,入门可参考https://zhuanlan.zhihu.com/p/33316527
吐槽归吐槽,下面放出实现方案,以及调试过程中各种形式的收益比较
以下结论来自https://www.kaggle.com/c/freesound-audio-tagging-2019
1 | ### x_mel_shape ( time_steps, frequency, channels) |